
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
今回の記事では、データ利活用支援・コンサルティングの老舗であるマクロミルの知見が盛り込まれた「データ利活用の教科書 データと20年向き合ってきたマクロミルならではの成功法則」から現役データサイエンティストの私が得た学びを紹介していきたいと思います。
本書は対象者をデータサイエンティストのような統計学やエンジニアリングに特化した専門家に限定しておらず、データ分析を行うにあたっての論点の整理やマーケティングの考え方、データを集めるための調査の設計の仕方など、データ利活用をしたい!と考えている方にとって広く有用な書籍となっています。
本記事では本書の中から私が学びになったと思ったエッセンスを抽出して紹介させていただきますので、ご参考にしていただけると幸いです!
本書の概要
データ利活用支援の経験を踏まえ、データ利活用のステップごとに必要なビジネス知識・スキルを整理したのが本書です。各知識・スキルをデータ利活用と関連づけて整理しており、「データ利活用に関する知識を体系的に学べる基本テキスト」であることが本書の特長です。
株式会社マクロミル/渋谷智之『データ利活用の教科書 データと20年向き合ってきたマクロミルならではの成功法則』(翔泳社/2023) P4
本書は意識データや購買データなどに基づいたデータ利活用支援・コンサルティング業務に従事しているマクロミルの知見が多く盛り込まれた1冊です。
本書の特徴としてはデータ利活用に関するTipsが載っているのみならず、データ利活用に際して必要となるスキル・知識についても詳細に解説されていることが特徴として挙げられます。
例えば、データを利活用する場面として非常に多いマーケティングに関連したTipsや、データ利活用の前提として課題を特定し、仮説を立て、問題を解決して行くために必要なロジカルシンキング・仮説思考などについて解説されています。
データ利活用という一種の手段と目的の逆転が起きてしまいがちな分野に関して、事前に目的側のマーケティング・仮説思考や目的から手段に降ってくるためのロジカルシンキングを補強しているのは、データ利活用初心者にとっても非常に易しい設計となっているのではないでしょうか。
本書の章立ては以下のようになっています。
- 第1章 日本におけるDX、データ利活用の現状
- 第2章 データ利活用に必要な知識・スキル
- 第3章 マーケティング
- 第4章 ロジカル・シンキング、ロジカル・コミュニケーション
- 第5章 仮説思考
- 第6章 問題解決ステップ
- 第7章 データ統合基盤・データ活用規制の動き
- 第8章 リサーチを活用した1次データの収集
- 第9章 データ分析
- 第10章 レポーティング&プレゼン
章立てを見ていただいてもわかるように、データ分析に関する部分はあまりボリューミーでなく、データ利活用の前段となるスキルと、データ利活用のアウトプットとなるレポーティングにページが割かれていることが分かります。
本書から得た学び
現役DSである私が本書から得た学びは以下の3点です。
- 問題解決のステップの再確認
- 実務観点での必要なサンプル数は400:30
- レート・シェア分析という可視化
順を追って解説していきます。
問題解決のステップの再確認
「問題の特定(WHERE)」で、どこに問題があるかを絞り込み、「原因の深堀り(WHY)」で、問題の原因を掘り下げて根本原因を特定します。その後、「打ち手の考察(HOW)」で、原因に対する対策を検討していきます。
株式会社マクロミル/渋谷智之『データ利活用の教科書 データと20年向き合ってきたマクロミルならではの成功法則』(翔泳社/2023) P144
人は何か問題が発生した時に、短絡的思考に陥ってしまうことがあります。
例えば、飲食店で売り上げが低下した場合に、「売上が低下したので売上を伸ばす必要がある」という小泉論法で考えてしまうと、そのロジックから出てくるHOWはチープなものになってしまいがちです。
例えば、売上は顧客数$\times$顧客単価に分解でき、顧客数は営業時間が長くなれば長くなるほど増加すると考えれば、「営業時間を長くする」という施策(HOW)が考えられます。
ですが、店舗としての施策をこのような裏返しの論理(売上が下がったなら売上を上げればいい)で考えていいのでしょうか?
このような短絡的な施策が最終的な結論とならないためには、WHERE→WHY→HOWの順番に則って問題解決を行う必要があります。
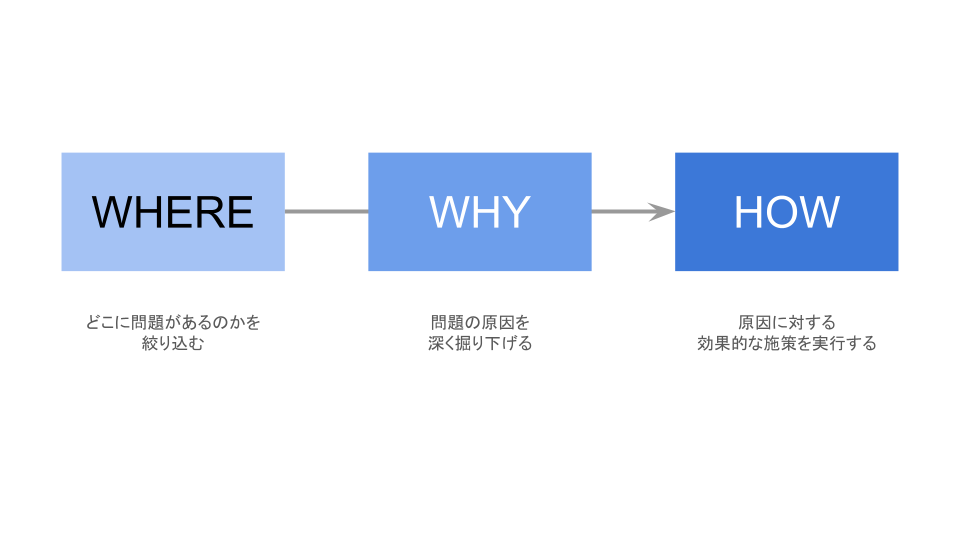
そして、上記の検討にデータ分析という切り口が手段として活用できるのです。
例えば、「売上低下」という事象の問題点はどこにあるのかを探りにいきます。
先ほど少し実施した売上という構成要素の分解を行うと以下のように分解できることが分かります。
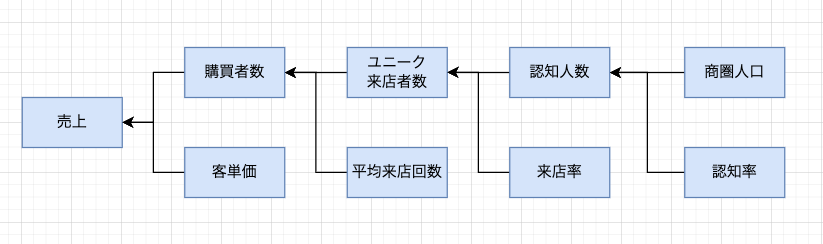
そして、それぞれの構成要素はデータという切り口である程度の可視化が可能です。
購買者数は「会計が行われた回数」として考えることができるので、POSレジに記録があるものと思われます。
客単価は売上$\div$購買者数で求めることができ、購買者数と客単価をそれぞれ時系列で可視化を行うことにより、どちらが減少して結果として売上減少につながったのかを判断することができます。
そして、購買数が売上減少の要素であった場合には、「ユニーク来店者数が減った」(=来店する人が減った)のか、「平均来店回数が減った」(=来店する頻度が減った)のかをデータを元に判断していきます。
このようにして、ロジックツリーに分解し、なおかつ可視化されたデータから売上減少の問題箇所を探っていくことによってWHEREの特定が完了します。
なお、上記のロジックツリーで問題箇所らしき問題箇所が見当たらない場合は別の切り口のロジックツリーを元に考えるか、ロジックツリーの抜け漏れを考える必要があります。
今回の例で言えば、「UberEats等の宅配購買数」については考慮していないので、もしかしたら真の問題箇所はそちらのロジックツリーになるかもしれません。
そして、要因が特定できたら、「なぜその問題箇所が減少してしまったのか」を深堀して考え、最終的な原因に対して施策を検討することによって、効果的な対策を打つことが可能になるのです。

実務観点での必要なサンプル数は400:30
実務的観点では「全体で400サンプル、分析単位ごとに最低30サンプル」と言われることが多いです。分析単位で30サンプルに満たない場合は、「参考値」と言われることが多いので注意が必要です。ただし、30サンプルの最大誤差は$\pm$18.3ptもあります。著者は「誤差が安定し始める80サンプルを分析単位ごとに確保する」ことをお勧めしています。
株式会社マクロミル/渋谷智之『データ利活用の教科書 データと20年向き合ってきたマクロミルならではの成功法則』(翔泳社/2023) P198
母集団から全てのデータを取得して分析をすることができない場合は、母集団の中から特定のサンプルを抽出して分析をする必要があります。
視聴率調査なども全ての家庭の番組視聴情報を集めるのは無理なので、一部の家庭の番組視聴情報を使って視聴率を算出していますよね。
全員に調査できない以上、標本を使った分析には標本特有の誤差がつきまといます。
例えば、平均点が50点の30人クラスから3人を選んで標本平均を再計算しようとする時、たまたま抽出した3人の点数が40点, 70点, 100点という点数であったら、標本の平均値は70点と母集団の平均点よりも20点ほど高い結果となってしまいます。
一方で、標本として抽出する人数を3人から20人に増やしたら、母集団の平均50点に近しい数字が得られるはずということは想像に固くないでしょう。
このように、母集団から標本を抽出して母集団の平均値などを推定する場合には、どれだけの数を標本として抽出するか、というサンプル数を決めておくことが重要になります。
逆に言えば、母集団を完全に再現できない以上、標本誤差は必ず存在してしまうため、「どれだけの標本誤差であれば最終的に導きたい結論を導くのに問題がないか」から逆算してサンプルサイズを導く必要があります。
そして本書で紹介している400サンプル、30サンプル、80サンプルはサンプリング誤差早見表によると、最大誤差がそれぞれ5pt、11.2pt、18.3ptとなっています。
私がこの情報が役立つと感じたのは、実務の中で少ないサンプルを使用してグループ間の違いを分析する$\chi^2$検定を行う必要があった時です。
あるグループのサンプルが4人と非常に少なかったので、
「クライアントに説明する際になんと言おうか、、、サンプルが少ないから標本誤差が大きく分析結果の妥当性が、とか言っても伝わらないよな、、、」
と悶々としていた中で、本書の上記一節を読みました。
「なるほど、30サンプル以下は参考値です、という風に伝えれば一旦は納得してもらえそうだし、追加で追及があった時に統計的な文脈をご説明すればいいのか」
と、クライアントへの報告の方向性のヒントを得たため、本内容をご紹介させていただきました。
レート・シェア分析という可視化
レート・シェア分析とは、セグメントごとに「レート(増加率)」と「シェア(割合)」の散布図を作成し、各セグメントの特異点を抽出する分析手法です。1時点だけでなく、時間軸を組み合わせることで、セグメント間の差異を見つけやすくなります。
株式会社マクロミル/渋谷智之『データ利活用の教科書 データと20年向き合ってきたマクロミルならではの成功法則』(翔泳社/2023) P258
市場シェアという指標は、顧客の購買意向の中のどのポジションにいるのかを知る上で、メーカーにとっては非常に重要な指標です。
実際に、私が現在参画している企業の営業部門でも市場シェアという指標はBIツールで可視化して追跡をしています。
一方で、市場シェア以外の切り口で見る必要があるのではないか?と考えていた中で本書で出会ったのがレートシェア分析です。
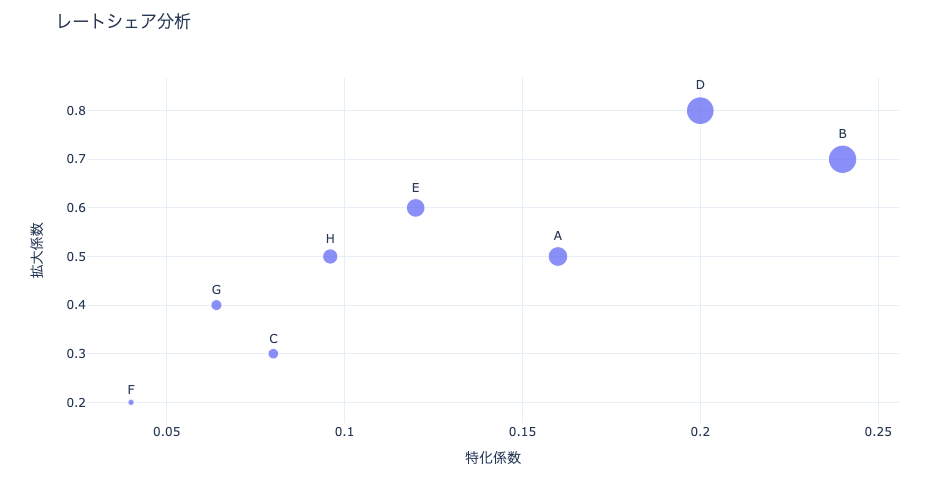
レートシェア分析とは、横軸に特化係数、縦軸に拡大係数を取って散布図に表したものです。
特化係数というとわかりずらいかもしれませんが、要するに自社内の売上構成比のような指標です。
$$特化係数 = \frac{当該商品のシェア}{自社全体の商品シェア} = \frac{当該商品の売上}{自社全体の商品売上}$$
なお、ここでいう「売上」に金額を設定するのか、個数を設定するのかは分析意図によって変更する必要があります。(市場シェアを換算する場合に一般的なのは金額です)
そして、拡大係数というのは自社全体の成長に比してその商品(またはセグメント)がどれだけ成長しているのかという指標です。
$$拡大係数 = \frac{当該商品の増加率}{自社全体の商品増加率}$$
ここでいう「増加率」というのは前年比や前月比での売上増加率と解釈しました。
このような分類を行うと、自社商品の中のどこに注力すべきかが明らかになるものと思われます。
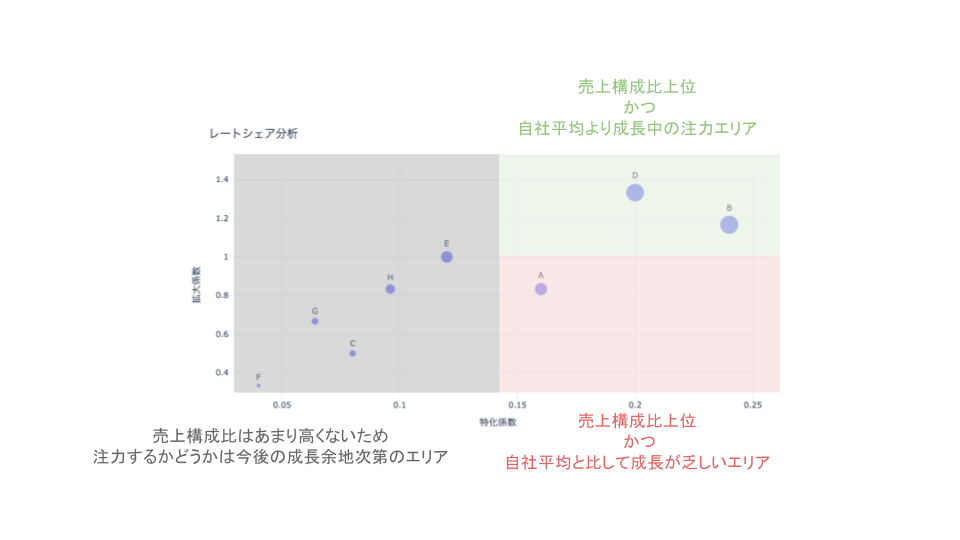
ただし、私が学びになった事項はレートシェア分析の内容そのままではなく、市場シェア率と成長率的な指標を2次元で見ることの重要性です。
上記可視化では、X軸もY軸も自社内に閉じた指標であるため、外部環境との比較が少ししにくいのではないかと考えています。
そのため、上記レートシェア分析の考えを応用して、現場では以下のような可視化を行なっています。
- X軸はセグメント市場シェア率(=自社におけるセグメントの売上金額/市場全体におけるセグメントの売上)
- Y軸は市場比セグメント成長率(=自社の当該セグメントの昨年比/市場全体の当該セグメントの昨年比)
- 2023年の散布図と2024年の散布図を同一プロットに描画し、同一セグメント同士を点線で結ぶことで昨年からの推移を可視化
シェアレート分析を上記のように変更することによって、以下のような示唆を得る目論みです。
- 市場シェア上位かつ市場比成長中の「花形」の特定(=注力エリア)
- 市場シェア上位かつ市場比現状維持の「金のなる木」の特定
- 市場シェア下位かつ市場比現状成長中の「問題児」の特定
- 市場シェア停滞かつ市場比停滞中の「負け犬」の特定(=非注力エリア)

さらなる可視化改良可能性
本来的には「花形」「金のなる木」「問題児」「負け犬」というのは横軸に市場シェア、縦軸に市場自体の成長率を取って可視化すべきものなので、元来の定義からは上記可視化はずれています。
上記可視化の意味合いとしては【市場全体が成長していると仮定した場合に】自社プロダクトのシェア率と市場比成長率の関係を可視化したグラフになります。
本来的な意味合いで考えれば、横軸は市場シェア率で固定で
- 縦軸: 市場全体の成長率(マクロ)
- 縦軸: 自社商品の成長率(自社に閉じている)
という2つのグラフを見比べ、市場の成長率に比して伸び悩んでいるところに注力する、という意思決定の方が施策に活かしやすいかもしれません。
まとめ
今回の記事では、データ利活用支援・コンサルティングの老舗であるマクロミルの知見が盛り込まれた「データ利活用の教科書 データと20年向き合ってきたマクロミルならではの成功法則」から現役データサイエンティストの私が得た学びを紹介させていただきました。
今回の記事は、私がプロジェクトの中で気づきがあった項目について紹介させていただいたので、データ分析・可視化に関する少しコアな内容について紹介しましたが、本書自体はデータ利活用に足を踏み入れた方々にも活用していただける内容が盛りだくさんとなっています!
データ利活用についてまずは体系立てて学びたい!という方はぜひ本書を手に取って読んでいただくことをおすすめいたします!


コメント