
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
本記事では、RAGを実装した生成AIアプリの作成に欠かせないLangChainというライブラリについて、自分で実装しながら学ぶことができる書籍『ChatGPT/LangChainによるチャットシステム構築[実践]入門』から得た学びについて、厳選して3つご紹介いたします!
本書はPythonについてある程度理解している方であれば誰でも挑戦できるほど、分かりやすくLangChainについて書かれている1冊になります!
「RAGについての知見を深めたい」「社内で生成AIに関する機運が高まっているので、生成AIを使った簡単なアプリを作れるようになりたい」という野心あふれる方におすすめの書籍です!
本書の概要
この書籍は、ChatGPTとLangChainを使って、大規模言語モデル(LLM)を本番レベルのシステムに組み込むための知識を、ステップバイステップで手を動かしながら学習できる実践書です。
吉田真吾、大嶋勇樹『ChatGPT/LangChainによるチャットシステム構築[実践]入門』(2023/技術評論社) Piii
本書は、RAG機能付きのLLMアプリを作成する際に欠かすことのできないLangChainについて、実際に手を動かしてWebアプリやSlackアプリを作りながら学ぶことができる、学習教材としてのポテンシャルが非常に高い1冊です。
本書の章立ては以下のとおりです。
- 第1章 大規模言語モデル(LLM)を使ったアプリケーションを開発したい!
- 第2章 プロンプトエンジニアリング
- 第3章 ChatGPTからAPIを利用するために
- 第4章 LangChainの基礎
- 第5章 LangChainの活用
- 第6章 外部検索、履歴を踏まえた応答をするWebアプリの実装
- 第7章 ストリーム形式で履歴を踏まえた応答をするSlackアプリの実装
- 第8章 社内文書に答えるSlackアプリの実装
- 第9章 LLMアプリの本番リリースに向けて
上記を見ていただいてわかるように、プロンプトエンジニアリングやChatGPTからのAPI取得など、LLM開発における基礎の部分から扱っているため、LLMエンジニアしか読めない本、というよりは、システム開発を専門とされる方やPythonでのコーディングについて一定の知識がある方であれば誰でも挑戦できる1冊となっています。
[本書読了前] 本書から得たい学び
本書読了前に、私が本書から得たかった学びは以下の3つです
- チャットシステム構築におけるプロンプトエンジニアリングの重要性
- LangChainとデータベースを接続したRAGの実装
- LangChainを使用した実用可能なWebアプリケーションの作成
1つ目の項目については、現在の研修業の中で必要な知見であるため、2つ目と3つ目についてはLLMを使用した自身の課題解決の幅を広げるためにRAG周りの実装力を身につけたいと考えていました。

[本書読了後] 本書から得た学び
私が本書から得た学びは以下のとおりです。
- Streamlitを使用したチャットアプリの作成は検索/メモリ機能込みでも超簡単
- Function Callingによる特定の形式での出力は意外と便利
- LangChainライブラリ周りは書籍出版当時(2023年10月)と状況が異なり、多少の自主的なキャッチアップが必要
順を追って解説していきます。
Streamlitを使用したチャットアプリの作成は検索/メモリ機能込みでも超簡単
本書ではLangChainとWebアプリ作成用のPythonライブラリStreamlitを使用してチャットアプリの作成に挑戦します。
以下のスクリーンショットは、実際に私が本書のサンプルコードを参考に作成したStreamlitのチャットアプリでLLMとチャットしている様子です。
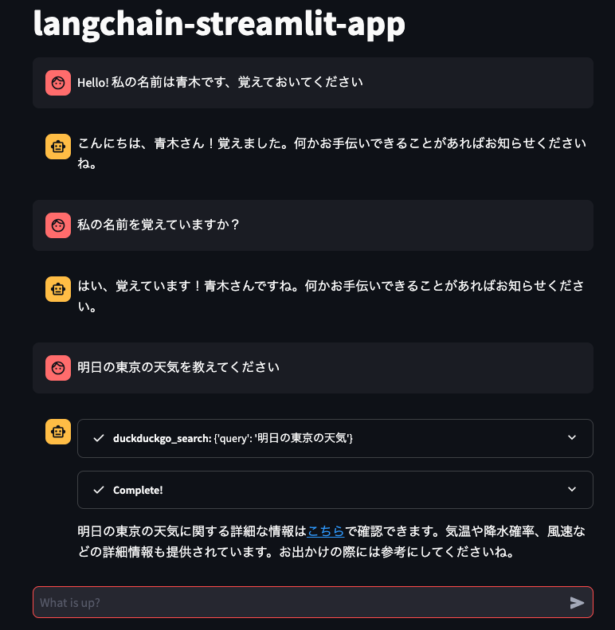
このチャットアプリには以下のような機能が実装されています。
- 過去の会話を覚えておくMemory機能
- 適切な回答を返すために、以下の機能を選択して使用する機能
- Wikipedia内を検索する機能
- Duckduckgoという検索エンジンを使って検索する機能
上記のリストを見ると分かるように、「目的を達成するためにはどのような機能を使う必要があるか?」を考えるAIエージェント的な機能もチャットアプリ内では実行されています。
なお、上記チャットアプリは以下のコードによって実行されており、最新のコードは書籍専用のGithubレポジトリに公開されています。
#%%
import streamlit as st
import os
from dotenv import load_dotenv
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
from langchain.agents import AgentType, initialize_agent, load_tools
from langchain.callbacks import StreamlitCallbackHandler
from langchain.memory import ConversationBufferMemory
from langchain.prompts import MessagesPlaceholder
load_dotenv()
# 1. AIエージェントの設定
def create_agent_chain():
chat = ChatOpenAI(
model_name = os.environ['OPENAI_API_MODEL'],
temperature = os.environ['OPENAI_API_TEMPERATURE'],
streaming = True
)
agent_kawrgs = {
'extra_prompt_messages': [MessagesPlaceholder(variable_name='memory')],
}
memory = ConversationBufferMemory(memory_key = 'memory', return_messages=True)
tools = load_tools(['ddg-search', 'wikipedia'])
return initialize_agent(tools, chat, agent = AgentType.OPENAI_FUNCTIONS, agent_kwargs=agent_kawrgs, memory = memory)
if 'agent_chain' not in st.session_state:
st.session_state.agent_chain = create_agent_chain()
# 2. チャットアプリのデザインの設定
st.title('langchain-streamlit-app')
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message['role']):
st.markdown(message['content'])
prompt = st.chat_input('What is up?')
# 3. チャットの応答ロジックの設定
if prompt:
st.session_state.messages.append({'role': 'user', 'content': prompt})
with st.chat_message('user'):
st.markdown(prompt)
with st.chat_message('assistant'):
callback = StreamlitCallbackHandler(st.container())
response = st.session_state.agent_chain.run(prompt, callbacks = [callback])
st.markdown(response)
st.session_state.messages.append({'role': 'assistant', 'content': response})
# %%
.envファイルにGPTのAPIキー、使用するGPTモデル、出力のばらつき(Temperature)の設定値を記載し、load_dotenv()関数で読み込んでいます。
上記コードを一瞥していただくと、以下の3つの構成要素でチャットアプリができていることがお分かりいただけるかと思います。
- AIエージェントの設定
- 使用するGPTモデルや出力のばらつき(Temperature)の設定
- 会話履歴を保存するメモリの設定
- AIエージェントが使用するツール(機能)の設定
- チャットアプリのデザインの設定
- チャットの応答ロジックの設定
- ユーザーの入力したプロンプトの表示
- AIエージェントの実行と出力結果のアプリ上への表示
このように、自身のローカルのPC上で動くチャットアプリであれば、検索機能やメモリ機能をつけたとしても比較的容易に動くものを作ることができる、というのが本書から得た学びです。
Function Callingによる特定の形式での出力は意外と便利
先ほどのStreamlitチャットアプリにも登場したように、LangChainにおいては「ツール(tool)」を指定することによってAIエージェントが使える機能を拡充することができます。
# この部分でAIエージェントが使うツールを指定しています
tools = load_tools(['ddg-search', 'wikipedia'])ところで、AIエージェントにツールという形で機能を拡充させることができることは分かりましたが、ツールを実行する(例: Wikipediaを検索する)のもプロンプトへの応答を作成するのと同様にOpenAIのサーバー上で行なっているのでしょうか?
実は、「使用するツールを選定する」のはOpenAIのサーバー上で行われていますが、実際に「Wikipediaを実行する」などの機能を実行しているのはプログラムを実行しているパソコン、今回の例で言えば私のパソコン上でツールの機能が実行されています。
つまり、OpenAIのサーバー側にあるChatGPTのAPIとPythonプログラムが動いている私のパソコンの挙動は以下の図のようにまとめることができます。
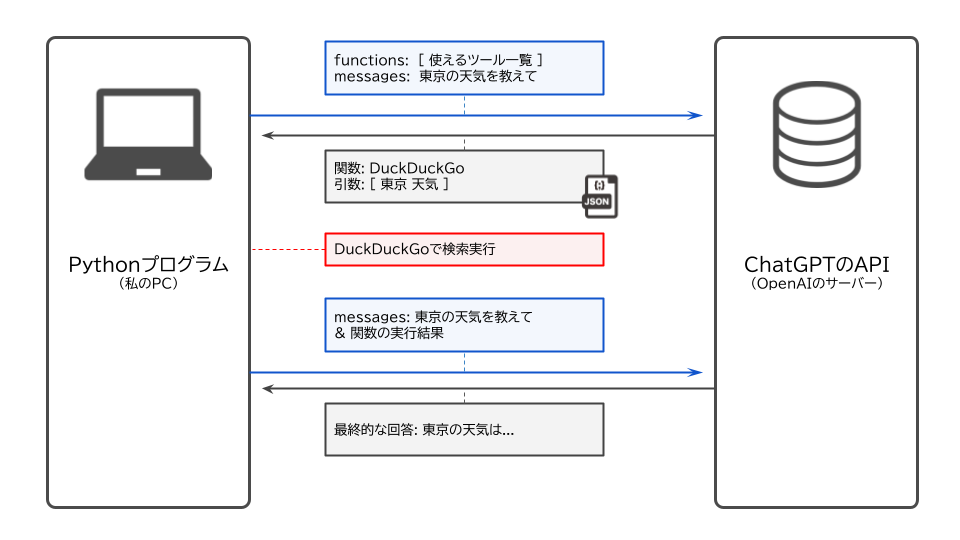
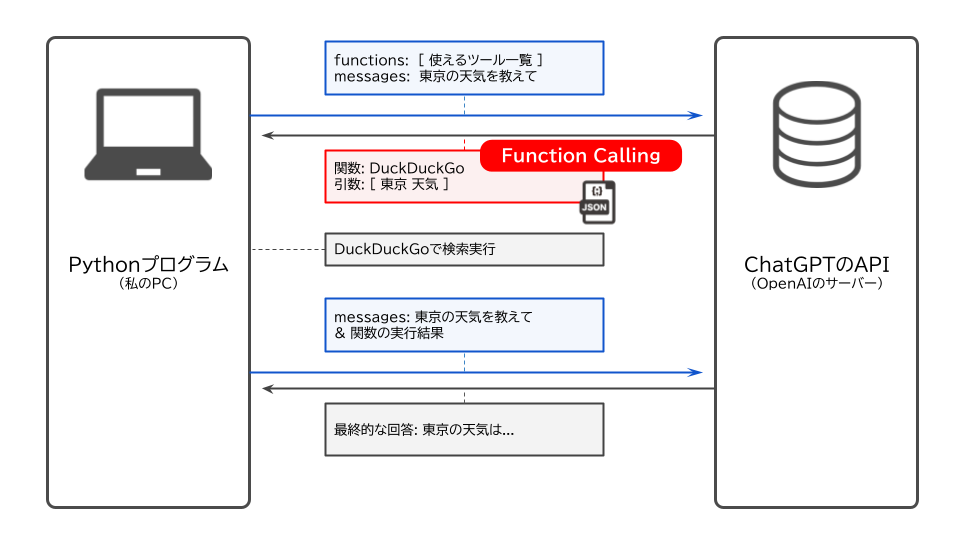
ここで今回注目したいのは、「どのFunctionを使えばいいか?」という質問をChatGPTのAPI経由で尋ねた際に、回答がJSONという形式で帰ってきている点です。
JSON形式とは、以下に例を示すように構造化されたデータ形式といえます。
my_data = {
'basic_information': {
'name': 'Aoki Kazuya',
'sex': 'Man',
'birth': '1995-11-05',
'country': 'Japan',
},
'change_information': {
'job': 'Data Scientist',
'age': 29,
'work_place': 'Tokyo',
'live_place': 'Kanagawa'
}
}上記は基本的には変わらない情報(basic_information)と変化する可能性のある情報(change_information)ごとに情報が並べられており、ある程度構造化されています。
このような形で「どの関数を使えばいいのかを構造化したデータ(JSON形式)で返してくれる」LLMのAPIの機能のことをFunction Callingと言います。
そして、Function Callingは「使用する関数を答える」以外にも使えるんだよ、という例が本書には紹介されています。
例えば、みなさんが「東京の1時間後の天気を表示するWebアプリ」を作成しているとしましょう。
Webアプリ上で東京の1時間後の天気を表示する際には、以下のようなJSONファイルを読み込んで天気を表示しているとします。
weather = {
'prefecture': 'Tokyo',
'city_name' : 'Shinagawa',
'date': '2025-01-07',
'time': '12:00',
'weather': 'sunny',
'temperature': 23.4,
}そして、このような構造化されたデータを検索結果から抽出したい場合に、Function Callingを応用することができるのです。
DuckDuckgoで検索した結果が変数search_resultに入っており、出力してほしい形式が変数schemaに記述されている場合、create_extraction_chain()関数を利用することによって、以下のコードを実行することによって構造化された情報を取り出すことができます。
import json
from langchain.chat_models import ChatOpenAI
from langchain.chains import create_extraction_chain
schema = {
'properties': {
'prefecture': {'type': 'string'},
'city_name' : {'type': 'string'},
'date': {'type': 'string'},
'time': {'type': 'string'},
'weather': {'type': 'string'},
'temperature': {'type': 'integer'},
},
'required': ['prefecture', 'date', 'time', 'weather', 'temperature']
}
search_result = """
...
天気予報 トップページ 2024年1月7日 12時 \t\t\t 天気: 東京 \t\t\t 23.5°C, 晴れ
\n\n 天気: 神奈川 \t\t\t 24.2°C, 曇り
...
"""
chat = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = create_extraction_chain(schema, chat)
people = chain.run(text)
print(json.dumps(people, indent=2))上記コードを実行すると、次のようにschemaで定義した構造化された情報が変数search_resultから抽出されます。
なお、以下の結果では、city_nameに関する情報は検索結果に記載がなかったため、記載されていません。
weather = {
'prefecture': 'Tokyo',
'date': '2025-01-07',
'time': '12:00',
'weather': 'sunny',
'temperature': 23.5,
}ChatGPTなどの生成AIサービスにおいてはFew-shotなどの手法を用いて出力をコントロールする場面がありますが、LangChainのFunction CallingではFew-shotよりも厳密に出力を制限することができる、というのが本書から得た学びです。
LangChainライブラリ周りは書籍出版当時(2023年10月)と状況が異なり、多少の自主的なキャッチアップが必要
本書は2023年10月に出版されており、ブログ主が本記事を書いている2025年1月は出版から約1年が経過しています。
そのため、LangChainの使用にもところどころ変更があり、本書記載のコードでも十分動くものの、 一部コードはLangChain開発側からはdeprecated(非推奨)とされています。
例えば、LLMモデルやプロンプト、出力形式の指定を組み合わせて高度なことをしたい場合には、LangChainのChainsを使用して、以下のようにコード上で表現することができます。
chain = LLMChain(prompt = prompt, llm = chat, output_parser = output_parser)一方で、2025年1月現在においては上記のLLMChainを使用した記法はdeprecated(非推奨)とされており、代わりにLCEL(LangChain Expression Language)というLangChain特有の記法が推奨されています。
chain = prompt | llm | output_parser上記の修正は簡単な修正でしたが、上記変更に従ってChainsを使用する際のMemoryの読み込ませ方などにも影響が及んでいるため、本書の内容からより発展的なことをしたい場合は自力での調査が欠かせません。
LangChainに関する情報を自力でキャッチアップするところも含めて、本書は大変勉強になる1冊でした。

本書推奨のAWSやクラウドベクターDBを意地でも使わず実装がんばってみた
最後に、ブログ主が本書で推奨されているAWSを使用した実装やクラウドのベクターDBのサービスを使用せずに本書と同じことを実現しようとしたコードの一部を皆さんに紹介したいと思います。
上記のようなことをした動機としては、「過去にAWSにRedshiftのシームレスサーバーを立てたら、ほとんど使っていないのに月20万ほどの請求が来て、泣きそうになりながらAWSに請求を撤回してもらえるよう泣きついた」という非常に情けない過去があるため、意地でもAWSに何かを建てたくなかったからです。
上記のような制約の中で本書と同じことを実現しようとすると、以下のような様々な仕様変更が必要となります。
- 本書で紹介されているクラウドのベクターDBはAWSとの接続を前提としているため、ローカルにベクターDBを用意する必要がある
- 本書で紹介されているクラウドのベクターDBを利用しないため、そのベクターDBに特化したLangChainの関数を使用できない
- 上記ベクターDBに特化したLangChainの関数を前提としてSlackアプリが開発されているため、Slackアプリとの通信部分についても自身で調べて実装する必要がある
- Slackアプリに対する応答はAWSサーバー上ではなくローカルPC上で行うため、応答用のプログラムを起動する必要がある
そして、上記のような仕様変更と先ほど紹介した「LCELへの変化」が合わさると、調査して実験しての繰り返しで実装に結構な時間がかかるようになります。
特に、LCELでの過去チャット履歴の保持についてはかなり苦労をしました。
また、上記の問題とは別で「PDFをベクトル形式でベクターDBに格納する際に、本書推奨のUnstructuredPDFLoaderがうまく作動しない」というエラーも発生したため、急遽PyPDFLoaderで代用するなどの対策を講じました。
苦労の末、ギリギリ動く状態に仕上がったのが以下のコード達です。
app.py
import os
from dotenv import load_dotenv
from slack_bolt import App
import time
from typing import Any
import re
from langchain import hub
from add_document import initialize_vectorstore
from langchain.chains import create_retrieval_chain, create_history_aware_retriever
import concurrent.futures
from langchain_openai import ChatOpenAI
from slack_bolt.adapter.socket_mode import SocketModeHandler
from langchain.callbacks.base import BaseCallbackHandler
from langchain.schema import LLMResult
from langchain.memory import ConversationBufferWindowMemory
from langchain_core.output_parsers import StrOutputParser
from datetime import timedelta
from langchain.schema import HumanMessage, LLMResult, SystemMessage
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.messages import BaseMessage
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from pydantic import Field
from typing import Sequence
import openai
from langchain.chains import LLMChain
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, HumanMessagePromptTemplate
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.runnables import RunnablePassthrough
load_dotenv()
model = os.environ['OPENAI_API_MODEL']
CHAT_UPDATE_INTERVAL_SEC = 1
SLACK_BOT_USER_ID = os.environ['SLACK_BOT_USER_ID']
openai.api_key = os.environ['OPENAI_API_KEY']
class LimitedChatMessageHistory(ChatMessageHistory):
max_messages: int = Field(default = 10)
def __init__(self, max_messages = 10):
super().__init__()
self.max_messages = max_messages
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
super().add_messages(messages)
self._limit_messages()
def _limit_messages(self):
if len(self.messages) > self.max_messages:
self.messages = self.messages[-self.max_messages : ]
from langchain_core.chat_history import BaseChatMessageHistory
store = {}
memory = LimitedChatMessageHistory(max_messages = 5)
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = memory
return store[session_id]
class SlackStreamingCallbackHandler(BaseCallbackHandler):
last_send_time = time.time()
message = ""
def __init__(self, channel, ts):
self.channel = channel
self.ts = ts
def on_llm_new_token(self, token: str, **kwargs) -> None:
self.message += token
now = time.time()
if now - self.last_send_time > CHAT_UPDATE_INTERVAL_SEC:
self.last_send_time = now
app.client.chat_update(
channel = self.channel, ts = self.ts, text = self.message
)
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
app.client.chat_update(channel= self.channel, ts = self.ts, text = self.message)
app = App(token = os.environ['SLACK_BOT_TOKEN'],
signing_secret = os.environ['SLACK_SIGNING_SECRET'],
process_before_response= True)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
def send_chat_request(memory, input_message: str):
try:
prompt = hub.pull('langchain-ai/chat-langchain-rephrase')
llm = ChatOpenAI(model_name = model)
vectorstore = initialize_vectorstore()
retriever = vectorstore.as_retriever()
chat_retriever_chain = create_history_aware_retriever(
llm ,retriever, prompt
)
response = chat_retriever_chain.invoke(
{'input': input_message }
)
return response
except Exception as e:
return f"エラー発生: {e}"
def call_function_with_timeout(func, timeout_seconds, *args):
with concurrent.futures.ThreadPoolExecutor() as executor:
future = executor.submit(func, *args)
try:
response = future.result(timeout = timeout_seconds)
return {'result': response}
except concurrent.futures.TimeoutError:
return {'error': "Function execution timed out"}
def remove_slack_id_from_text(text, slack_id):
return text.replace(f"<@{slack_id}>", "")
def create_prompt():
messages = [
SystemMessage(content = "Assistant is a large language model trainied by OpenAI."),
HumanMessagePromptTemplate.from_template('{human_input}')
]
# prompt = PromptTemplate(input_variables=['history', 'human_input'], template=template)
prompt = ChatPromptTemplate.from_messages(messages)
return prompt
@app.event('message')
def handle_message_events(body):
return None
@app.event('app_mention')
def handle_mention(event, say):
input_message = event['text']
thread_ts = event.get('thread_ts') or None
channel = event['channel']
user_id = event['user']
prompt = create_prompt()
input_message = remove_slack_id_from_text(input_message, SLACK_BOT_USER_ID)
timeout_seconds = 2 * 60
response = call_function_with_timeout(send_chat_request, timeout_seconds, memory, input_message)
if "error" in response or response['result'] is None:
reply_text = f'<@{user_id}>\nごめんなさい。現在サーバーの負荷が高いため処理できませんでした。時間をおいて再度質問してください。'
else:
reply_text = response['result']
reply_text = f'<@{user_id}>\n{reply_text}'
if thread_ts is not None:
parent_thread_ts = event['thread_ts']
say(blocks = [
{
'type': 'section',
'text': {
'type': 'mrkdwn', 'text': reply_text
}
},
{'type': 'divider'},
{'type': 'context', 'elements': [{'type': 'mrkdwn', 'text': "OpenAI APIで生成される情報は不正確または不適切な場合がありますが、AOKIの見解を述べるものではありません。"}]}
],text = reply_text, thread_ts = parent_thread_ts, channel = channel)
else:
response = app.client.conversations_replies(channel= channel, ts = event['ts'])
thread_ts = response['messages'][0]['ts']
say(blocks = [
{
'type': 'section',
'text': {
'type': 'mrkdwn', 'text': reply_text
}
},
{'type': 'divider'},
{'type': 'context', 'elements': [{'type': 'mrkdwn', 'text': "OpenAI APIで生成される情報は不正確または不適切な場合がありますが、AOKIの見解を述べるものではありません。"}]}
],
text = reply_text, thread_ts = thread_ts, channel = channel)
if __name__ == '__main__':
SocketModeHandler(app, os.environ['SLACK_APP_TOKEN']).start()add_document.py
# %%
import logging
import os
import sys
from uuid import uuid4
from langchain_community.document_loaders import PyPDFLoader
from dotenv import load_dotenv
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_community.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
load_dotenv()
logging.basicConfig(
format = "%(asctime)s [%(levelname)s] %(message)s", level = logging.INFO
)
logger = logging.getLogger(__name__)
def initialize_vectorstore():
embeddings = OpenAIEmbeddings()
index = faiss.IndexFlat(len(embeddings.embed_query('hello world')))
vector_store = FAISS(
embedding_function=embeddings,
index = index,
docstore=InMemoryDocstore(),
index_to_docstore_id={}
)
file_path = 'jdlasg2023_report.pdf'
loader = PyPDFLoader(file_path)
raw_docs = loader.load()
print(raw_docs)
logger.info("Loaded %d documents", len(raw_docs))
text_splitter = CharacterTextSplitter(chunk_size = 300, chunk_overlap = 30, separator = '')
docs = text_splitter.split_documents(raw_docs)
logger.info("Split %d documents", len(docs))
vector_store.add_documents(docs, ids = [str(uuid4()) for _ in range(len(docs))])
return vector_store
# %%上記コードを実行する際には、.envファイルにGPTのAPIキーなどの情報を事前に記入しております。
なお、クラウドのベクターDBの代わりに今回の実装ではFaissというローカルで動くベクターDBを採用しました。
上記コードを python app.py で実行すると、BoltというアプリのようなものがローカルのPC上で起動し、Slackアプリからの問い合わせに対応できるようになります。
試しに、LLMアプリに対してメンションをつけて「AIガバナンスについて教えて」と質問をすると、ベクターDBから類似した情報を検索して、以下の動画のように回答をしてくれます。
上記実装は調査して試しての繰り返しであったため、かなり難航を極めましたが、RAGを実装し、その中身について理解するという観点では価値ある経験ができたと認識しています。
まとめ
本記事では、RAGを実装した生成AIアプリの作成に欠かせないLangChainというライブラリについて、自分で実装しながら学ぶことができる書籍『ChatGPT/LangChainによるチャットシステム構築[実践]入門』から得た学びについて、厳選して3つご紹介いたしました!
本書では実際にWebアプリやSlackアプリを実装しながらLangChainについての理解を深めることができるため、非常に楽しく学習を進めることができました。
また、ブログ主はローカル環境での実行にこだわって実装を進めましたが、適切にAWSのリソースを管理しながら実装を進めることができる方であれば、本書の実装に従えばより簡単にLangChainについての理解を深めることができます。
LangChainについて理解を深めたい方は、ぜひ本書をお手に取って、その上でご自身なりのAIアプリを開発してみてください!


コメント