
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
この記事では、CLIPテキストエンコーダーのtext_model._build_causal_attention_maskを実行しようとすると、AttributeErrorが出る場合の対処法についてご紹介したいと思います!
Stable Diffusionに対してCLIPテキストエンコーダーを使用している人で同じようなエラーにぶち当たっている人に本記事の解決策が届くと幸いです!
エラーの内容
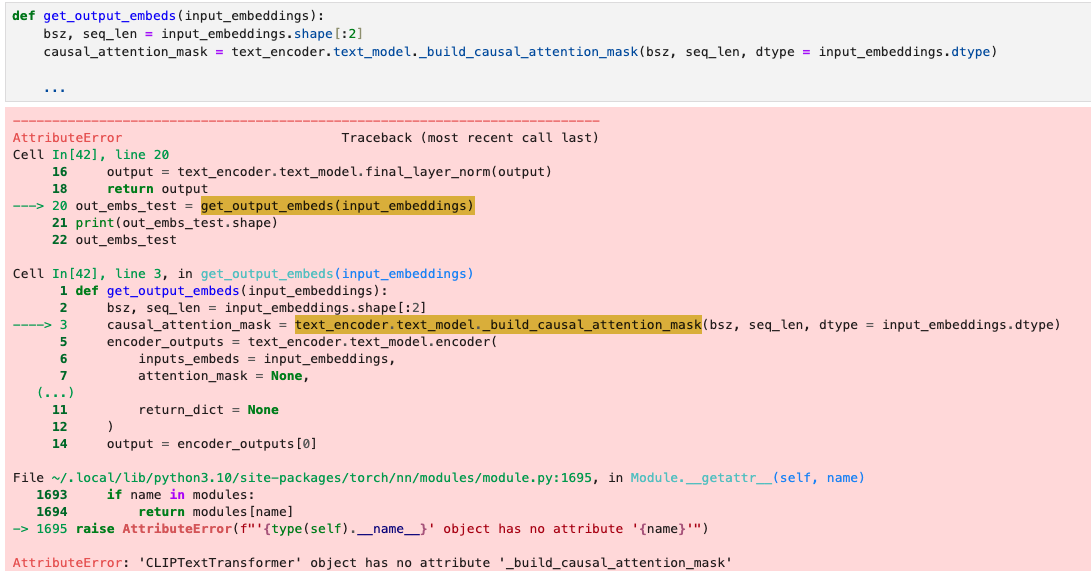
私の場合はPractical Deep Learning for CodersのChapter9: Stable DiffusionのLesson9A Videoの解説の中で、Stable Diffusionに渡すためのEmbeddingを作成する関数において、CLIPテキストエンコーダーのtext_model._build_causal_attention_maskを使用しようとしたところで、AttributeErrorが出力されてしまいました。
つまり、現在のCLIPテキストエンコーダーのtext_modelには_build_causal_attention_maskというメソッドは存在していないようです。
########## 関数定義のための前準備
# ライブラリのインポート
import torch
from transformers import CLIPTextModel, CLIPTokenizer, logging
# CLIPテキストエンコーダーの読み込み
checkpoint = 'openai/clip-vit-large-patch14'
text_encoder = CLIPTextModel.from_pretrained(checkpoint)
# GPU使用可否の判断
torch_device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
def get_output_embeds(input_embeddings):
bsz, seq_len = input_embeddings.shape[:2]
causal_attention_mask = .text_encoder.text_model._build_causal_attention_mask(bsz, seq_len, dtype = input_embeddings.dtype)
encoder_outputs = text_encoder.text_model.encoder(
inputs_embeds = input_embeddings,
attention_mask = None,
causal_attention_mask = causal_attention_mask.to(torch_device),
output_attentions = None,
output_hidden_states = True,
return_dict = None
)
output = encoder_outputs[0]
output = text_encoder.text_model.final_layer_norm(output)
return outputエラーの原因
今回のエラーの原因はGithubのIssueによると「Transformersライブラリのアップグレードによる仕様変更」が原因のようです。
以上のことから対応方針として以下が考えられます。
- Transformersを_build_causal_attention_maskが存在するバージョンにダウングレードする
- _build_causal_attention_maskと同等の関数を作成し、それを適用する
本記事では上記2つの方針のうち、2つ目の方針での解決策についてご紹介いたします。
1つ目の方針については、すでにインストールされている他ライブラリのバージョンとの互換性の問題でダウングレードしないケースもございますので、ダウングレードされる場合は慎重に行っていただけると幸いです。
ダウングレードする場合にコマンドラインツールで実行すべきコマンドを以下に記載しておきます。
pip install -q --upgrade transformers==4.25.1 diffusers ftfy修正版のコード
修正の方針は「_build_causal_attention_mask」と同等の関数を定義して、置き換えることです。
以下に修正版のコードを提示いたします。
########## 関数定義のための前準備
# ライブラリのインポート
import torch
from transformers import CLIPTextModel, CLIPTokenizer, logging
# CLIPテキストエンコーダーの読み込み
checkpoint = 'openai/clip-vit-large-patch14'
text_encoder = CLIPTextModel.from_pretrained(checkpoint)
# GPU使用可否の判断
torch_device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
# _build_causal_attention_maskと同等の関数を定義
def build_causal_attention_mask(bsz, seq_len, dtype):
mask = torch.empty(bsz, seq_len, seq_len, dtype = dtype)
mask.fill_(torch.tensor(torch.finfo(dtype).min))
mask.triu_(1)
mask = mask.unsqueeze(1)
return mask
def get_output_embeds(input_embeddings):
bsz, seq_len = input_embeddings.shape[:2]
# 同等の関数で置き換え
causal_attention_mask = build_causal_attention_mask(bsz, seq_len, dtype = input_embeddings.dtype)
encoder_outputs = text_encoder.text_model.encoder(
inputs_embeds = input_embeddings,
attention_mask = None,
causal_attention_mask = causal_attention_mask.to(torch_device),
output_attentions = None,
output_hidden_states = True,
return_dict = None
)
output = encoder_outputs[0]
output = text_encoder.text_model.final_layer_norm(output)
return output以下が上記のコードに対して実行をした場合の結果になります。
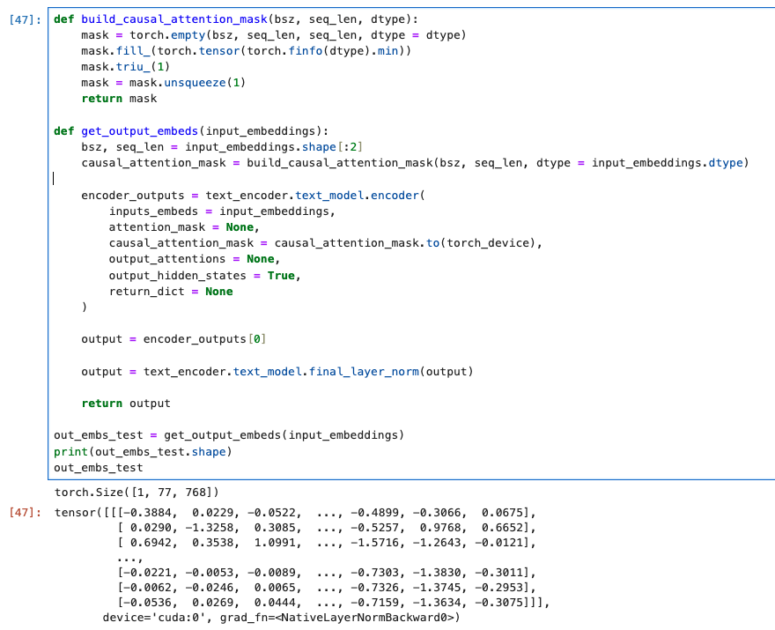
get_output_embs関数が正常に実行されていることが確認できます。
まとめ
今回の記事では、CLIPテキストエンコーダーのtext_model._build_causal_attention_mask()を実行すると、AttributeError: ‘CLIPTextTransformer’ object has no attribute ‘_build_causal_attention_mask’が出る時の対処法について解説いたしました!
CLIPテキストエンコーダーはDiffusion Stableに文字情報を入れるときに必要になってくるので、この記事を見て同じエラーに当たった人は解決できることを願っています!


コメント