
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
今回の記事では、SAPからBigQueryにETLツールを使ってデータ連携をする際に「なんでバイナリ型のデータがGCPに入れたら勝手に変換されてるん???」ということが起きたので、その事象の仕組みについて、僕なりに調べて結果を解説していきます。
バイナリデータに触れたのが初めてで苦戦したので、同じような疑問にぶち当たった人に届けばいいなと思っております!
時間がない人のための3行解説!
SAPのバイナリデータ「RAW型」
SAPにはDATS型やCHAR型など、さまざまなデータ型が存在しますが、当記事で扱うのは「RAW型」と呼ばれるBinaryデータです。
Binary(バイナリ)データとは
Binaryという言葉はもともと「2進数」を表す言葉です。
2進数とは0と1でさまざまな数字を表現する方法です。
そして、コンピューターが内部で我々のプログラムを処理するときは「print(‘Hello World!’)」のような人間が読めるコードを「000101011101000101」のような機械語に翻訳してプログラムを実行しています。

つまり、コンピューターは「Binary( = 0または1)」を処理してプログラムを実行していると言えます。
そこから転じて、Binaryデータというのは「コンピューターだけが読むことができるデータ」のことを指すことがあります。
たとえば、SAPのRAW型データは以下のInfomaticaのサイトではBinaryとして分類されていますが、後述の通り中身は16進数です。
参考:SAPデータ型
たとえば、RAW型データの例としては「010101」や「AA123」などの16進数のバイナリデータがあります。
BigQueryのバイナリデータ「BYTES型」
一方でBigQuery型は「BYTES」と呼ばれるデータ型にバイナリデータを格納しています。
このBYTES型は一癖あり、なんとBigQuery内にインサートされる時にはbase64、つまり64進数表現でインサートされる必要があるのです。
そしてインサート元のデータが64進数以外のバイナリデータであった場合には問答無用に64進数に変換するという仕様になっています。
そのため、SAPから入ってきたRAW型データ(=16進数)はBigQueryにインサートされる時に強制的にbase64(=64進数)に変換されてしまうのです。
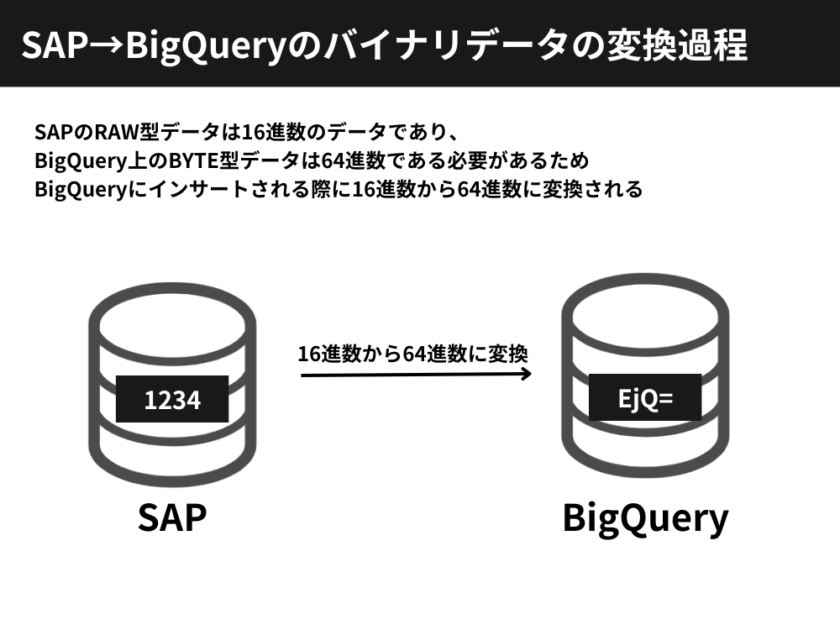
SAP to BigQueryの変換をPythonのbase64モジュールで再現してみる
それでは、SAPの16進数バイナリデータがBigQueryでどのように64進数に変換されていくのか、Pythonのbase64モジュールを使用して確かめてみましょう。
base64モジュールとは
base64モジュールとはPythonに標準搭載されているバイナリデータのエンコード/デコードができる便利ツールです。
このモジュールを使えば文字列→base64(=64進数)といったエンコード処理やbase64→文字列といったデコードを処理を行うことができます。
また今回の検証で使用するように、16進数へのエンコード/デコードを行うこともできます。
エンコード/デコードとは
エンコードとは「文字を決められた規則に従って、他の形に変換すること」のことを言います。
そしてデコードはその反対で「エンコードによって変換された文字を元の形に戻す」ことを指します。
今回の例で言えば、文字列→base64をエンコード、base64→文字列をデコードと呼んでいますが、これは起点を文字列とした時の話であって、起点をbase64とすれば、base64→文字列がエンコード、文字列からbase64がデコードということもできます。
今回の例では、SAP側で「1234」という16進数バイナリデータをETLツールを使ってGCPのBigQueryにインサートする時のことを考えましょう。
ここで、Pythonで以下のように記載してSAP側のバイナリデータを用意したとしましょう。
# SAP側の16進数バイナリデータ?
sap_binary_data = b'1234'なんで文字列の前にbをつけるの?
PythonやBigQueryにおいては、「この文字列は普通の文字列じゃなくてバイト列だよ!」ということを明示するために、文字列の前にbyteのbをつけます。
たとえば、BigQueryのBYTES型にデータをインサートするときも、文字列の前にbをつけてないと「BYTES型に普通の文字列は入れられないよ!」とエラーが出てしまいます。
バイト列ってなに?
バイト列を理解するためには、そもそも「バイトってなに?」というところから理解する必要があります。
そして、バイトを理解するためには「ビット」について理解する必要があります。
そして、ビットを理解するために必要なものは、実はすでに出てきている「バイナリ」です
ビットとは、バイナリ、つまり0と1の2進数で表した数字の桁数のことです。
だから、4ビットと言われれば「1101」や「1011」のような数字のことを言いますし、8ビットと言われれば「10110100」や「11101010」のような数字のことを指します。
そして、バイトとは、そのまま8ビットのことです。
なので、1バイトと言われれば「10110100」や「11101010」のような数字のことを指します。
実はこの書き方は正しくはありません。
なぜなら、SAPで「1234」と見えるデータは私たちの思っている数字の「1234」とは異なるからです。
SAPのBinaryの「1234」とPythonのバイト列の「1234」が異なる理由
たとえば、より簡単な例で2進数と10進数を例に挙げて考えてみましょう。
たとえば2進数で「111」と記載されていますが、これは10進数の世界の「111」と同じでしょうか?
2進数を学んだことがある人であれば、2進数の世界における「111」は10進数の世界における
「111」(ひゃくじゅういち)ではなく「7」であるということがわかるはずです。
逆に言えば、10進数の世界における「111」は2進数の世界においては「1101111」と表現されます。
そして、10進数と2進数の関係と同じように、今回のSAP上で書かれた16進数の「1234」がPythonのバイト文字列の「1234」は見た目こそ同じですが、意味合いは全く異なる、ということを覚えていただきたいと思います。
実際のSAPからBigQueryのバイナリデータの変換過程を見てみる
それでは実際にSAPからBigQueryにバイナリデータが移行される時にどのような変換が発生しているのか見ていきましょう。
たとえば、SAPに「1234」というRAW型データが入っていたとします。
この時の「1234」というデータは16進数で表現されたデータです。
つまり、10進数における「1234」とは異なることに注意してください。
そして、この「1234」というRAW型データをETLツールを使ってBigQueryにインサートします。
すると、以下のようにbase64変換された「EjQ=」がBigQueryにインサートされたことが確認できるはずです。
PythonでSAP→BigQueryの16進数→64進数変換を再現してみた
それでは実際にPythonでSAPからBigQueryにデータが移行する際に発生している16進数から64進数への変換を再現してみましょう。
もし自身のSAPデータが本当に64進数に変換されているのか確認したい方は、以下のGoogle Colabにアクセスして、自身のGoogleドライブ環境にダウンロードをしていただいた上で、変数x_b16の0xの後ろに64進数に変換したい16進数のデータを書き込んで実行してみて下さい!
https://colab.research.google.com/drive/1QCBC9Jp3MeVh2KutuFJeCZ6R7UrC4jN4?usp=sharing
BigQueryにインサートされたデータと同じ形に変換が行われているはずです。
# ライブラリの読み込み
import base64
# 0xの後ろに変換したい16進数のデータを入れてね
# 例: 16進数「120503」を変換したい場合 -> x_b16 = 0x120503
x_b16 = 0x1234
# base64はバイト列しか引数として受け取れないので、16進数をバイト列に変換する
x_bytes = x_b16.to_bytes((x_b16.bit_length() + 7) // 8, byteorder='big')
# バイト列(16進数)をbase64(BigQueryのBYTESと同じデータ型)に変換する
x_b64 = base64.b64encode(x_bytes)
# 変換結果を見る
print('SAP : {} ===16進数から64進数へ===> BigQuery : {}'.format(format(x_b16, 'x'), x_b64))
0xは何を意味するの?
x_b16についている「0x」は「この後の数字またはアルファベットは16進数ですよ」ということを表しています。
このように、データの前に接頭語のようなものを「プレフィックス」と呼びますが、2進数、8進数、16進数のプレフィックスはそれぞれ0b、0o、0xです。
bin_num = 0b10
oct_num = 0o10
hex_num = 0x10
print(bin_num)
print(oct_num)
print(hex_num)
# 2
# 8
# 16to_bytesのところでは何をしているの?
to_bytes()は整数を表す16進数バイト列を返す関数です。

ここで、第1引数にはバイト列の長さを指定することができます。
この場合のバイト列とは16進数バイト列のことです。
なお16進数バイト列では、1バイトを使って10進数の0( = b”)から255(= b’\xff’)までを表すことができます。
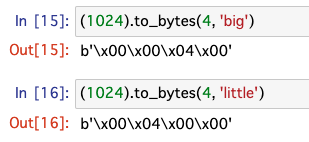
例えば、以下のように1024という10進数の数字をto_bytes()を使って、2バイト列を返すように指定すると、1024を16進数(\xつき)で表現したb’\x04\00’が返ってきます。

第2引数のbyteorderはbigを指定すればバイト列は左から大きい順に、littleを指定すればバイト列は左から小さい順に記載されます。
10進数で言うと、「115」という数字がbigと指定すると「115」と記述されて、littleと記述すると「511」と記述されるイメージですね。
to_bytes()の第1引数に書いてある「(x_b16.bit_length() + 7) // 8」って何?
1つ前のコラムでto_bytes()が何を表すのかについてはご理解いただけたかと思います。
それでは、ブログのコードにあるto_bytes()の第1引数に書かれている(x_b16.bit_length() + 7) // 8とは一体何を意味するのでしょうか。
これについて以下のように段階を追って考えてみましょう。
- bit_length()とは何か?
- 16進数1バイトは2進数の何バイト分まで表すことができるのか?
- x_b16.bit_length() + 7 の表す数は?
- (x_b16.bit_length() + 7) // 8 の表す数は?
1. bit_length()とは何か?
bit_length()は整数を二進数で表すために必要なビットの数を表します。
例えば、10進数の2は2進数で11と表されるので、(2).bit_length()は2です。
10進数の4は2進数で100と表されるので、(4).bit_length()は3です。

2. 16進数1バイトは2進数何バイト分まで表すことができるのか?
ここでbit_length() + 7 について考える前に、 16進数1バイトが2進数何バイト分まで表すことができるのかを考えてみましょう。
16進数1バイトで\x00から\xffまで表すことができます。
そして\x00は当然のことながら10進数でいう0を、\xffはf=15ですので、10進数で[mathjax]\(15 \times 16 + 15 = 255\)まで表すことができます。
ここで、2進数のことを考えてみると、1バイト=8ビットで00000000〜11111111まで表すことができます。
2進数の00000000は10進数で0、2進数の11111111は10進数で255を表します。
ここで、つまり10進数で0〜255までは2進数でも16進数でも1バイトで表すことができることがわかります。
ここで、考えなければならないのは、2進数9ビット、つまり1バイトよりも少し大きな2進数は16進数何バイトで表すことができるのでしょうか。
正解は2進数9ビットは16進数2バイトで表すことができます。
例えば、10進数でいう256は2進数では100000000(9ビット)で表されますが、16進数では\x01\x00、つまり2バイトで表されます。
同様に、2バイトより1ビット大きな2進数17ビットは、16進数3バイトで表されます。
つまり、[mathjax]\(8 \times x\)ビットより小さいビット数で表される場合は[mathjax]\(x\)バイトの16進数で表されるということです。
3. bit_length() + 7 は何を表しているのか?
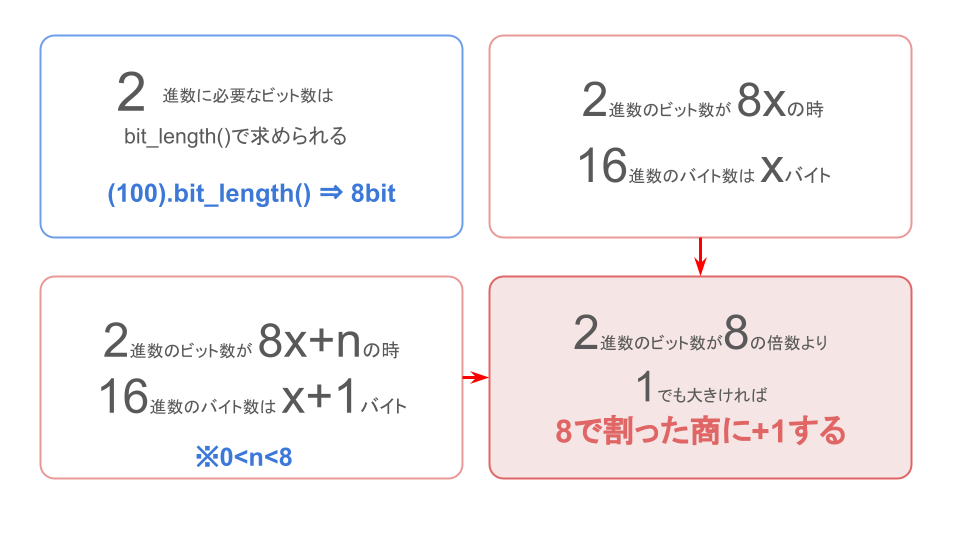
先ほどの話を整理すると、2進数のビット数と16進数のバイト数には以下のようなルールが成り立っています。
- ある10進数を2進数で表す時に必要なビット数はbit_lengthで求めることができる
- 2進数のビット数が8の倍数の時、つまり[mathjax]\(8x\)の時は、[mathjax]\(x\)バイトの16進数で表すことができる。
- 2進数のビット数が8の倍数でない時は、つまり[mathjax]\(8x + 1\)の時は、[mathjax]\(x + 1\)バイトの16進数で表すことができる。
- 2進数のビット数が8の倍数かどうかは、8で割った時に余りがあるかどうかで判断することができる
それでは、わざわざbit_lengthに7を足す意味はなんでしょうか。
その理由は、ルール3の「8の倍数でない時は[mathjax]\(x + 1\)バイトの16進数で表すことができる」という部分が少しわかりずらいことにあります。
8の倍数かどうかを判断するためには2進数のビット数を8で割る必要があり、8で割り切れなかった場合は8で割った時の商に1を足す必要があります。
実は、(x.bit_length() + 7 ) // 8 を考えた人は、この「1を足す」という動作を面倒くさがったのです。
それでは、bit_lengthに7を足すことのどのような点が良いのでしょうか。
それは、「余りを気にせずに8で割った時の商がそのまま16進数のバイト数になる」という点です。
4. ( bit_length() + 7 ) // 8 の表すものとは?
具体的な計算をして、( bit_length() + 7 ) // 8 が16進数で表す時のバイト数を表現していることを確認していきましょう。
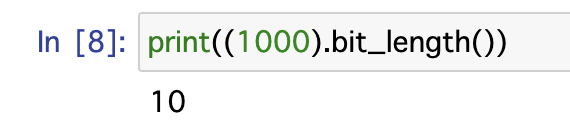
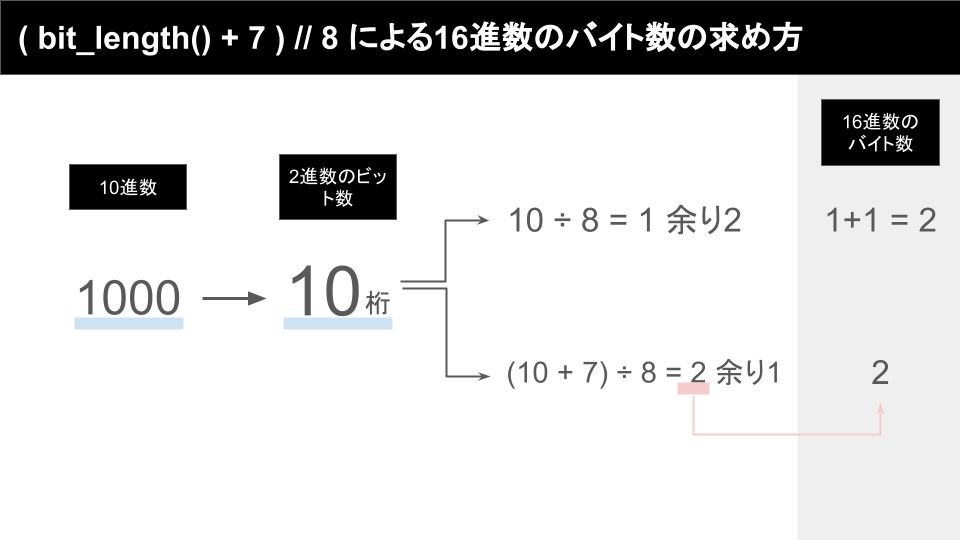
例えば、1000という数字について考えてみることにします。
bit_length()を使うと1000という数字は2進数では10ビットで表されることが分かります。
さて、10進数の1000は2進数では10ビットで表されるということは、8で割ると1余り2になるので、16進数で表す際には2バイト必要になることがわかります。
ここで、「2進数では10ビット」の10ビットに7を足すと18ビットになります。
そしてこれを8で割ると2余り1です。
つまり、7を足してから8で割った時の商2がそのまま16進数のバイト数になってくれるのです。
これが今回の( bit_length() + 7 ) // 8のカラクリです。
つまり、
「8で割った時、余りが出なかったら商がそのまま16進数のバイト数に、余りが出たら商+1が16進数のバイト数になる」
という求め方だったのが、2進数のビット数に7を足すことによって
「8で割った時の商がそのまま16進数のバイト数になる」と求め方が非常にすっきりするのです。
まとめ
今回の記事ではSAPからGCPのBigQueryにデータを移行する際の、16進数から64進数への変換過程について検証した結果を解説しました!
SAPからBigQueryのインサートでBYTES型のデータが書き換わるのはBigQueryの仕様上避けられないことなので、どのような変換が起こるのかを認識した上でSAPからBigQueryのデータが正常に移行されているかを確認するようにしましょう!
参考サイト
Binary関係のリンク
base64関連のリンク
バイト列関連のリンク
Pythonで2進数、8進数、16進数の数値・文字列を相互に変換

コメント