
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
今回の記事では、私が気になった「for range(len(df))でdfの各行を参照する」 場合と「for df.iterrows()でdfの各行を参照する」場合、どちらの方が性能的に優れているのかを検証してみようと思います!
そもそもiterrowsってどうやって使うの?
そもそもとして、df.iterrowsの使い方について解説していきましょう!
iterrows()はpandasのDataFrameの各行を参照、つまり、各行のデータを順番に見ていきたいときに使います!
たとえば以下のような使い方ができます
import pandas as pd
#数字が入った配列を作成
num_arr = [10, 20, 30]
#配列をDataFrameに変換
num_df = pd.DataFrame(num_arr, columns = ['num'])
#データフレームの中身をチェック
display(df)
#データフレームの各行を出力
for index, row in df.iterrows()
print(f'{index + 1}行目: {row['num']}')
上記のように、iterrows()を使うことによって、データフレームnum_dfから以下の2つを引き出すことができます。
- 今参照しているデータはデータフレームの中の何行目か(index)
- 今参照しているデータの行の情報(row)
2のrowには参照しているデータの行の情報全てが入っているので、row[‘num’]のような形で「行のどの部分を参照したいのか」を指定してあげることによって、データフレームの中の特定の情報を参照することができます。
たとえば以下の例では、row[‘num2’]と参照することによって、各行のnum2列の情報を引き出すことに成功しています。
import pandas as pd
#数字が入った配列を作成
num_arr = np.array([10,20,30,40,50,60])
#配列の形を 3行2列に変形
num_arr = num_arr.reshape(3,2)
#配列をDataFrameに変換
num_df = pd.DataFrame(num_arr, columns = ['num1', 'num2'])
#データフレームの中身をチェック
display(num_df)
#データフレームの各行を出力
for index, row in num_df.iterrows():
print(f'{index + 1}行目: {row["num2"]}')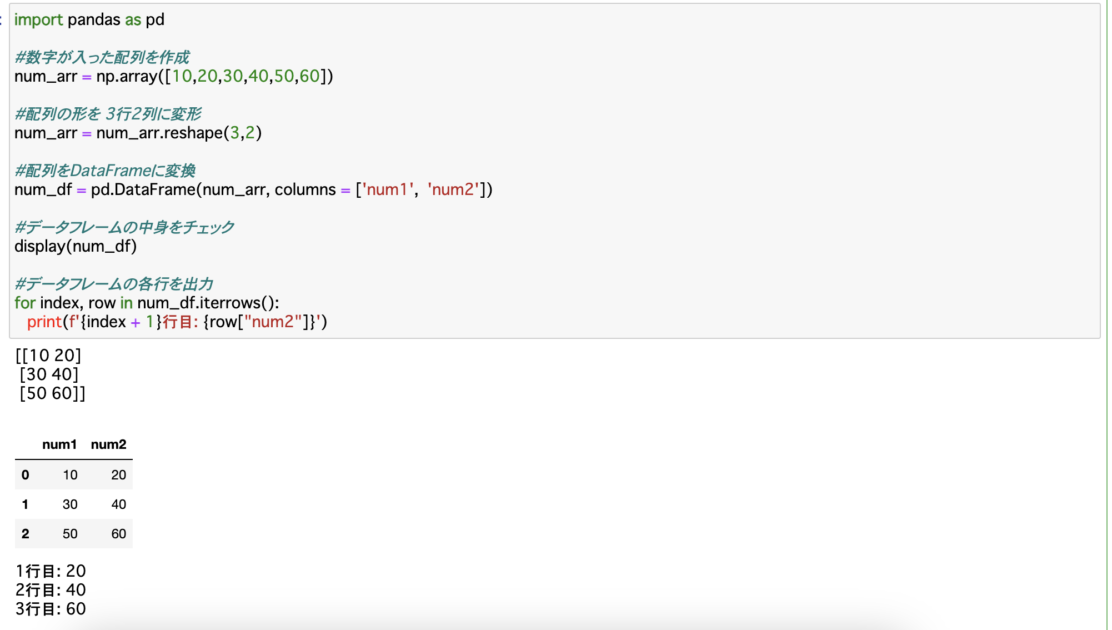
そして、上記のように各行のデータを出力する方法として、もう1つ、「for i in range(len(df))」を使うという方法が考えられます。
これはデータフレームの行数(=len(df))分処理を繰り返すfor文であり、そのような方法でも各行のデータを出力することができます。
import pandas as pd
#数字が入った配列を作成
num_arr = np.array([10,20,30,40,50,60])
#配列の形を 3行2列に変形
num_arr = num_arr.reshape(3,2)
#配列をDataFrameに変換
num_df = pd.DataFrame(num_arr, columns = ['num1', 'num2'])
#データフレームの中身をチェック
display(num_df)
#データフレームの各行を出力
for index in range(len(num_df)):
print(f'{index + 1}行目: ', num_df['num2'][index])または
import pandas as pd
#数字が入った配列を作成
num_arr = np.array([10,20,30,40,50,60])
#配列の形を 3行2列に変形
num_arr = num_arr.reshape(3,2)
#配列をDataFrameに変換
num_df = pd.DataFrame(num_arr, columns = ['num1', 'num2'])
#データフレームの中身をチェック
display(num_df)
#データフレームの各行を出力
for index in range(len(num_df)):
print(f'{index + 1}行目: ', num_df.at[index, 'num2'])上記の2つのコードはどちらも先ほどのJupyter notebookと同じ出力結果を得ることができます。
df.iterrows()とrange(len(df))に性能の面で違いはあるの?
さて、そこで湧いてくる疑問が「どちらも同じ動作をするなら、どちらを使った方がいいとかってあるの?」ということです。
実際に大きめのデータセットを使用して性能を比較してみましょう。
今回の検証用のデータセットとして、adult.csvという5MBのデータセットを用意しました。
このデータセットは収入予測のためのデータセットとしてパブリックに公開されているデータです。
以下のリンクからダウンロードすることができます。
https://www.kaggle.com/datasets/wenruliu/adult-income-dataset
まずはデータセットを読み込んで中身をみてみましょう。
後々の検証用にtqdmも読み込んでおきます。
import pandas as pd
from tqdm import tqdm
df = pd.read_csv('~/Downloads/adult.csv')
display(df)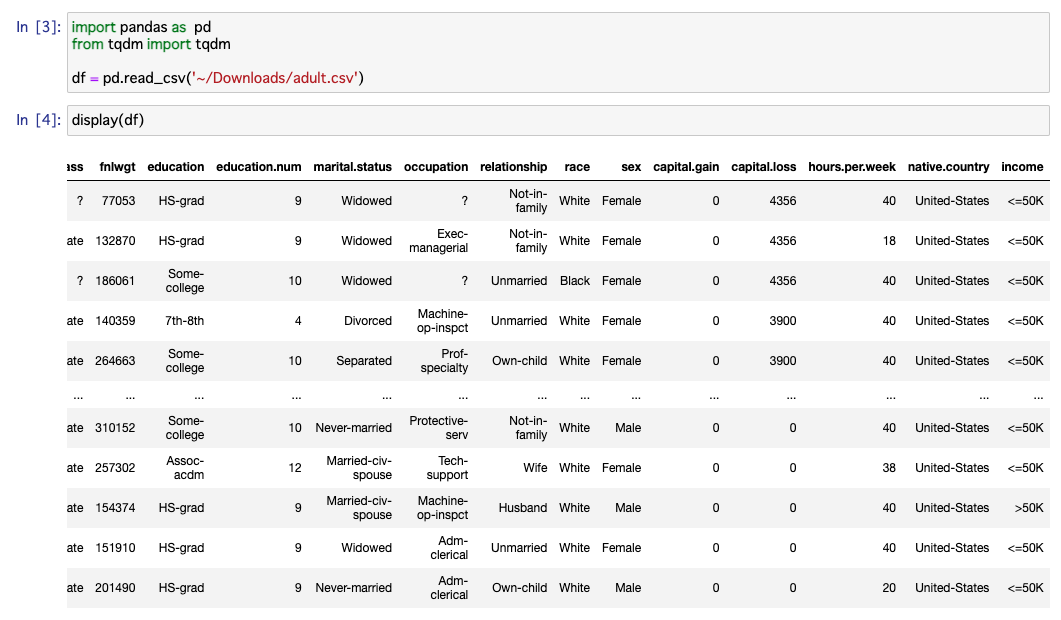
データセットを見てみると、一番右のカラムのincomeカラムが収入のレンジを示した目的変数のようですね。
それでは、incomeカラムを目的変数として2値変数である0と1に変換する処理をrange()で回すパターンとiterrowsで回すパターンで検証してみましょう!
まずは、以下のコードでrange()で回すパターンの場合にかかる時間を計測してみます。

結果を見てみると、実行時間は10秒で1秒あたり3228.67行分くらい処理してくれているようです。
一方で、iterrows()の方はどうでしょうか。

なんと、こちらは実行時間3秒で1秒あたり8297.88行分も処理を進めてくれたようです!
まとめ
今回の記事では、pandasのDataFrameで各行に処理を施す時にrange()とiterrow()のどちらで処理を回した方が早いのか検証してみました!
今回は5MBのデータで検証を回してみたので7秒ほどの差しかつきませんでしたが、大きなデータセットでは当然ながらより大きな差がつくことが予想されます。
皆さんもぜひdfの各行に処理を施す時はiterrows()を使ってみてください!
おまけ
ちなみに今回のような変換処理はpandasの一括処理を使った方が早く処理できます。
# mappingを作ってから実行するパターン
income_mapping = {
'<=50K': 0,
'>50K' : 1
}
df.income = df.income.map(income_mapping)
# mapの中に直接if文を書いちゃうパターン
df.income = df.income.map(lambda x: 1 if x == '<=50K' else 0)

コメント