
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
本記事では、ゼロつくシリーズ第2弾、書籍『ゼロから作るDeep Learning ❷ ―自然言語処理編』を読んで得た学びを厳選して3つご紹介いたします。
前作の『ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装』もゼロから作っているにも関わらず、非常に分かりやすかったのですが、本作も全くもって期待を裏切らない完成度で、ニッコニコで自然言語処理の裏側の仕組みについて理解を深めることができました。
本書は、もはやブームにもなっている生成AIの根底にある仕組みについて理解を深めたい方や、初心者機械学習エンジニアの方にお勧めです!
本書の概要
本作では、自然言語処理や時系列データ処理に焦点を当て、ディープラーニングを使ってさまざまな問題に挑みます。
斎藤康毅『ゼロから作るDeepLearning2 自然言語処理編』(オライリー・ジャパン/2018)Piii
そして、前作同様「ゼロから作る」をコンセプトに、ディープラーニングに関する高度な技術をじっくりと堪能していきます。
本書は、前作の『ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装』の続編となる通称ゼロつくシリーズの第2弾の書籍となっており、自然言語処理に関するトピックについて、読者自ら「ゼロから」実装していく本となっています。
世に自然言語処理に関する書籍は多々あれど、「ゼロから実装」しながらも「非常に分かりやすい」というバランスを保っている書籍は本書以外にないのではないでしょうか。
それほどまでに分かりやすい書籍となっているため、ディープラーニング初学者にもおすすめできる1冊です。
本書の章立ては以下のようになっています。
- 第1章 ニューラルネットワークの復習
- 第2章 自然言語と単語の分散表現
- 第3章 word2vec
- 第4章 word2vecの高速化
- 第5章 リカレントニューラルネットワーク(RNN)
- 第6章 ゲート付きRNN
- 第7章 RNNによる文章生成
- 第8章 Attention
本書の章立てをご覧になってもわかるように、自然言語処理というものがどのような歴史を辿ってきたか、当時の人がどのような課題感を持って次なるアルゴリズムを生み出したのかが体験できるような流れになっています。
本書から得たい学び
私が本書から得たい学びは以下の3つです。
- 自然言語処理において誤差逆伝播はどのように利用されているのか
- RNN/LSTMの実装
- Attentionの実装
昨今はTransformerモデルを使って簡単にファインチューニングや推論を行うことができるようになりました。
だからこそ、RNN、LSTM、Transformerの中身の部分について知らないままにそれらを利用している方も多いのではないでしょうか?
そのようなある種のパッケージ化されている部分について、本書を読み、1から作ることで理解を深めたいと考えています。

[本書読了後] 私が本書から得た学び
私が本書から得た学びは以下の3つです。
- 自然言語処理におけるアルゴリズムの変遷
- RNNが長期記憶を持てず、LSTMが長期記憶をそこそこ保持できるわけ
- Transformerが並列処理できるわけ
順を追って解説していきます。
自然言語処理におけるアルゴリズムの変遷
近年の自然言語処理においては完全にTransformerが主流も主流ですが、本書においては「人間がコンピューター用に辞書を作って、それを元に言語を解析する」という自然言語の原初のところから手を動かして学びことができます。
つまり、以下のような自然言語の変遷を学ぶことができるのです
- シソーラスによる手法: 類義語をまとめた辞書のようなものを作り、コンピューターに単語間の関連性を教える
- カウントベース: 「単語の意味は、周囲の単語によって形成される」という仮説に基づき、ある単語の周囲の単語の数を数えて行列で表現し、その行列から言葉の類似度を導く
- word2vecのCBOWモデル: 隣にあるトークン($\risingdotseq$単語)をディープラーニングで推論することで単語の意味を抽出したベクトルに変換する
- RNN: 前の文脈を加味して次の単語を予測することで、文脈を考慮した単語の意味を抽出する
- LSTM: RNNに「記憶」を保持/削除する機能を追加し、より長い文脈を考慮できるように改良
- Transformer: 単語のどこを注視すべきかという情報を付与するAttentionレイヤを導入することによって、言語理解の性能アップと並列計算を実現
上記自然言語処理の変遷は、すべて本書の中で実際に自分で一からコードを書いて、処理の内容を体験することができます。
もちろん、「ライブラリを使って時短!」などのようなことはしません。
全てを己が手で作りながら学んでいくのです。
現代においてはTransformerが当たり前となってしまいましたが、そこに至るまでにどのような試行錯誤をかつてのAI研究者たちが重ねてきたのか、その一端を垣間見ることができました。

RNNが長期記憶を持てず、LSTMが長期記憶をそこそこ保持できるわけ
「RNNは長期的な文脈を考慮できないが、LSTMはゲートによって長期的な文脈を考慮できる」
これは、G検定などで自然言語処理の変遷を学んだことがある人であれば、誰もが聞いたことのあるフレーズではないでしょうか。
そして、そのようなフレーズとともに「LSTMの仕組み」として以下のような図が提示されます。
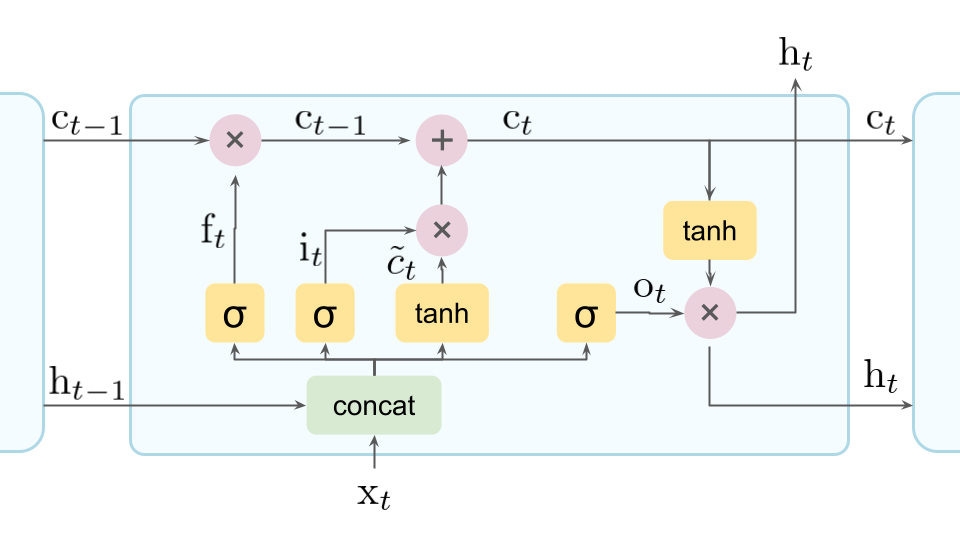
そして我々は思うのです。
「何がなんだかさっぱりわからん…」と。
そして、「LSTMの図解」に爆速で置いていかれた方にとっては朗報なことに、上記図の意味が誤差逆伝播含めすべて理解することができるのです。
以下は、LSTMの誤差逆伝播を計算する際に、ブログ主が書いた計算グラフです。
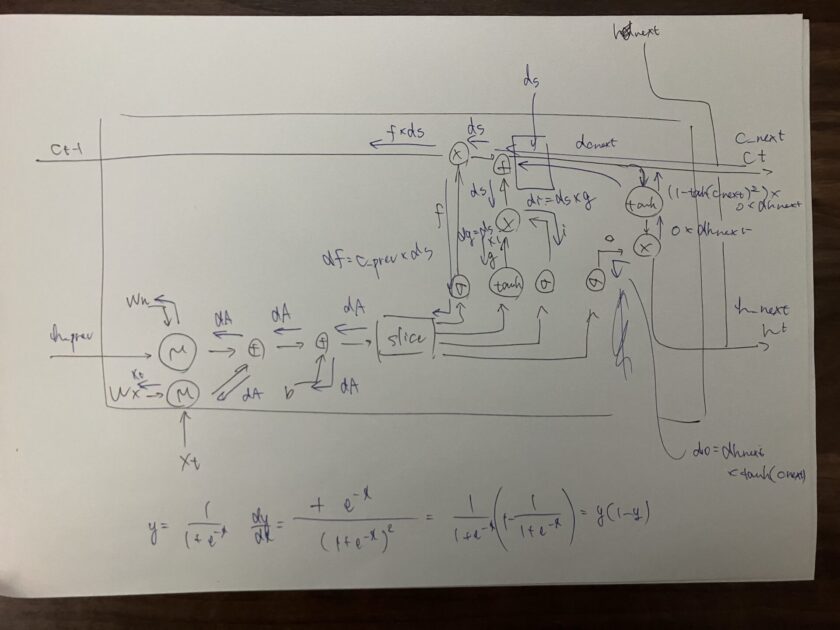
計算グラフとは
ゼロつくシリーズにおいて、順伝播と誤差伝播の説明をする際に用いられず図で、これがまた非常に理解しやすいです。
詳しくはゼロつく第1弾『ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装』について書いた書評で簡単な説明をしておりますので、そちらをご参照ください。

一見難解な図に見えますが、それぞれのパラメータの流れや演算について詳細に解説をしていただいているおかげで、誤差逆伝播の計算含め、めちゃくちゃ理解しやすいです。
「LSTMの仕組み、結局よく分からないんだよな…」という方は本書を読むことを激しくお勧めいたします。
Transformerが並列処理できるわけ
LSTMになると長期的な文脈を考慮した文章生成ができるようになるため、自然言語処理の精度としてはスタート地点のCBOWと比べてるとかなり改善しています。
一方で、「次の単語の生成に前の単語の情報を使う」というRNN/LSTMの特性上、順番に処理することしかできず、マシンパワーにモノを言わせた並列処理をすることができません。
そこで、登場するのが「どの単語に注目すればいいのか」という情報を与えてくれるAttention機構をうまいこと活用したTransformerというモデルです。
元々Attention機構は「LSTMの単語推論精度を上げたい!」という課題意識に対して、「前の文脈の情報をただ与えるだけでなく、次の単語では前の文脈のこの単語に注目して!のような付加的な情報を与えたらどうなるだろうか」という方針でLSTMに組み込まれたレイヤーになります。
そのような発想が転じて、「LSTM的要素を取っ払って、Attentionだけで頑張ってみたらどうなるのか」という試行錯誤の結果として、Transformerモデルが誕生したものと推察できます。
そして、RNNやLSTMのような「時系列的にデータを処理する」という要素を取っ払うと、それらのモデルに存在していた「順番に処理を実行しなくてはならない」という制約条件を取っ払われます。
それによって、GPUによる並列処理の恩恵を最大限受けることができ、「GPT-4」のような精度の高い文章生成ができるモデルが誕生したのです。

まとめ
本記事では、ゼロつくシリーズ第2弾、書籍『ゼロから作るDeep Learning ❷ ―自然言語処理編』を読んで得た学びを厳選して3つご紹介いたしました!
現代の生成AIのベースとなっている知見でありつつも、LSTMやTransformerはライブラリを動かしているだけでは、その中身としてどのような動きをしているのかは捉えづらいのが現状です。
そのようなある種わからなくても使えるものに対して、初学者でも分かるような解説と実装で切り込んでいく本書の展開には感動すら覚えます。
本書に興味を持った方は、ぜひお手に取って、本書の凄さと自然言語処理の先人たちの奮闘を体験してください!


コメント