
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
今回の記事では、データ分析の成功事例集ではなく、あえて失敗事例集を集めた「データ分析失敗事例集 失敗から学び、成功を手にする」について、現役データサイエンティストが得た学びを共有させていただきたいと思います!
この本はデータ分析における「こんな失敗あるよね〜」と思わず唸ってしまうような失敗集がフィクションながらもリアルに書き連ねられており、車の教習所で見るヒヤリハットの動画のような「明日は我が身かもしれない」と思わされる事例がこれでもかと詰められています。
本記事では、本書を読んで私が「この本で先に知ることができてよかった…」と思った事例を3選してみなさんにご紹介させていただきます。
本書の素晴らしさは私が選んだ3選にとどまらず、なんと25もの事例が載っていることなので、本記事を読んで気になった方はぜひ本書を手に取ってみてください!
本書の概要
本書が伝えたいことは、データの活用に関わる人々が、失敗を避けるために何をしてはならないのかということである
尾花山和哉/株式会社ホクソエム『データ分析失敗事例集 -失敗から学び、成功を手にする-』 (共立出版/2023) P5
本書はデータ分析の実務者の方々から寄せられた「失敗事例」をステークホルダーやプロジェクト概要、失敗に至るまでの経緯となぜ失敗してしまったのかの分析について詳細に書かれた、まさに転ばぬ先の杖以外の何者でもない1冊となっています。
つまり、この1冊があれば先人たちが落ちていった穴を避けて通る可能性を飛躍的に向上することができます。
また、データ分析事例についても、仮説検証からプロダクト開発、BI構築など多岐に及んでおり、データ分析に関わる方であれば必ず何かしらの学びを得られるような1冊となっています。
本書の章立ては以下のとおりです。
- Part Ⅰ 「えーあい」でなんとかして!
- CASE 1 UIを統一してUXが破綻する
- CASE 2 誰のための仕事? それが問題だ
- CASE 3 最先端アピールのための最先端プロジェクト
- CASE 4 本当に季節性はありますか
- CASE 5 レコメンドの必要ありますか
- CASE 6 分析を現場でどう使うか
- CASE 7 ほとんど故障しない製品の故障予知
- CASE 8 AIという言葉の曖昧さ
- CASE 9 そんな目的変数で大丈夫か
- コラム データサイエンティストとしての生き方
- Part Ⅱ 翻弄されるデータサイエンティスト
- CASE 10 成功した報告しか聞きたくない
- CASE 11 ターゲティングの必要性
- CASE 12 決定木分析は決定木だけではない
- CASE 13 ドメイン知識の重要性
- CASE 14 政治的な数字の応酬
- CASE 15 プロダクトアウトでもドメイン知識は大事
- CASE 16 スタイルの違いが引き起こした混乱
- CASE 17 いくら分析したところで、売れないものは売れない
- コラム データサイエンティストの人事事情
- Part Ⅲ その失敗を超えてゆけ
- CASE 18 カオス状態のBIレポート
- CASE 19 用意できたのは集計データのみ。予測精度はどこまで……
- CASE 20 取ってびっくり、こんなに使えるデータは少ないのか
- CASE 21 頑張って予測していたのは……
- CASE 22 木を見て森を見ずはキケン
- CASE 23 総人口の十倍を超えるID数との出会い
- CASE 24 最終報告が終わってから集計の仕様が決まる
- CASE 25 機械学習モジュールの寿命
- コラム 絶対に失敗しないデータ分析
章立ての内容を見ていただいても分かるように、機械学習などの中身の話だけでなく、前提の確認や関係者とのコミュニケーションなど、データ分析がビジネスに貢献する手段としたときに避けては通れないいくつもの壁についても失敗事例を紹介していただいています。
現役DSが学びを得たポイント
本書からは数えきれないほどの学びを得たのですが、その中でも私が特に「これは有用だ!」と思ったポイントは以下の3つです。
- そんな目的変数で大丈夫か
- 総人口の十倍を超えるID数との出会い
- 絶対に失敗しないデータ分析
順を追って解説していきます
そんな目的変数で大丈夫か
このケースは、最適なリスティング広告の出稿を行う機械学習開発のケースです。
Web広告はデータがWeb上で取れるが故にデータパイプラインが構築しやすく機械学習モデルの作成に向いていると本書では紹介されています。
このケースの中で私の学びとなってポイントは以下2つです。
- 割合の値は目的変数にするべからず
- その問題は回帰ではなく分類に帰着できないか
割合の値は目的変数にするべからず
今回の問題設定にあたって、目的変数はCTR(クリックスルーレート)に設定されました。
これはWeb広告などではよくKPIにされる数字で、表示された広告に対してどれだけのクリックを集めることができたかを表す指標です。
Webマーケティングを少しでも齧ったことがある方なら、CTR(またはCVR)あたりが目的変数になるのは何ら違和感はないかと思われます。
ですが、今回の機械学習モデル作成にあたってはこの目的変数の設定が大きな落とし穴でした。
なぜならば、CTRの計算式は以下のような式だからです。
$$\mathrm{CTR} = \frac{クリック数}{インプレッション数(広告表示数)}$$
そして、クリック数もインプレッション数も固定的な値ではなく、広告出稿側によって変動する余地のある値です。
すると、CTRを単独で予測しようとすると、インプレッション数とクリック数というそれぞれの誤差というものによってCTRについても増幅された誤差が発生してしまいます。
かといってインプレッション数を予測してから、その値をクリック数の予測に使用して最終的なCTRの予測に使用する、とすると、インプレッション数の予測モデルの誤差がクリック数の予測モデルの誤差に載ってしまうため、これまたCTRの予測値は誤差が増幅される形になってしまいます。
結局のところ、CTRは決して良い目的変数とは言えないのです。

その問題は回帰ではなく分類に帰着できないか
以上の結論から考えるに、取りうる選択肢は2つあると思われます。
- 回帰分析を行うとして、説明変数を別の指標に置き換える
- 回帰分析ではなく分類問題に置き換える
今回のプロジェクトについてはどのようなアプローチが取られたかというと、分類問題による解決の方向に舵を切りました。
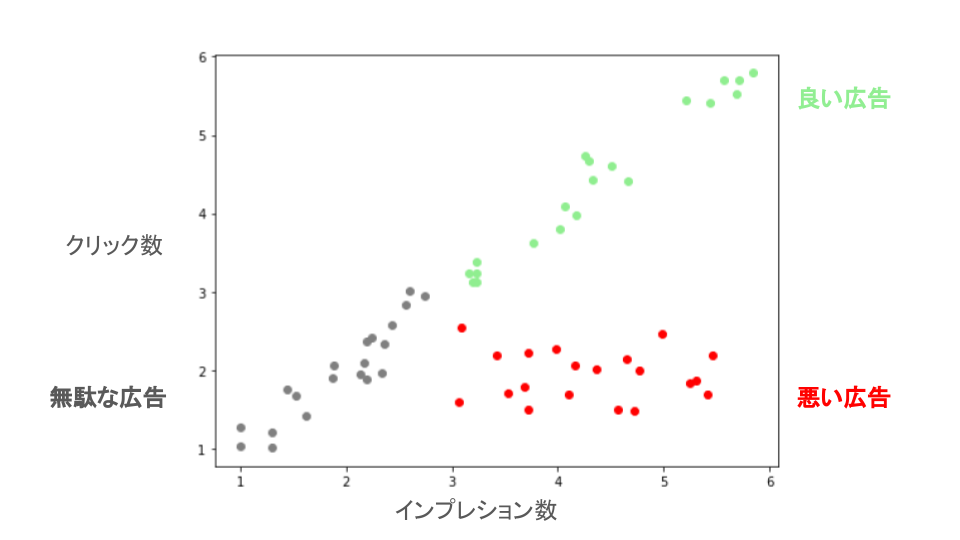
というのも、CTRがインプレッション数とクリック数から計算されるということは、それぞれの数を2軸に取ったときに、その大小によって「良い広告」「悪い広告」「無駄な広告」への分類が可能と考えたのです。
そして、それらの広告群への分類を行う分類問題へと舵を切ったのです。
分類は(回帰と比較して)高い精度を示すモデルを作れる可能性が高い。
またその指標として様々な値が存在し、プロジェクトのシステム的要件やセキュリティ的要件を鑑みて、相応しい指標を選び採用することが可能である。
尾花山和哉/株式会社ホクソエム『データ分析失敗事例集 -失敗から学び、成功を手にする-』 (共立出版/2023) P86
総人口の十倍を超えるID数との出会い
このケースの問題も先ほどと同様にWeb広告の最適化に関するケースです。
このプロジェクトは、5000万人規模のユーザーを抱えるIT企業で、ログインユーザーが500万人、非ログインユーザーが4500万人という構成になっていました。
そして、彼らが使用したブラウザに保存されたクッキー情報をもとに最適な広告を決定するモデルを作成しようと考えていました。
一方で、端末やブラウザごとに別のクッキーを使用しているため、ID数は非ログインユーザーが4500万人だとすれば、単純計算でその3〜5倍のクッキーが存在する、 つまり約1億〜2億件のクッキーが存在するというところまでは試算をしていました。
しかしながら、蓋を開けてみたら、10億件のクッキーが存在することが判明したのです。

ここから10億件のクッキーの謎に迫る過程も非常に興味深いので、詳しくは本書をご覧いただきたいのですが、今回のプロジェクトの肝となったのは、最初にクッキー数の概算をしていたことであると語られています。
つまり、何の概算もなしには「10億件」というクッキー数を疑うことはないですし、誤った前提に立った分析は誤った結論を導いてしまいます。
・「違和感」を大切にする
集計したのでコードを確認して終わり、ではなく「違和感」を感じた場合は時間の許す範囲で深堀すべきである。
そこが問題発見の出発点となる
尾花山和哉/株式会社ホクソエム『データ分析失敗事例集 -失敗から学び、成功を手にする-』 (共立出版/2023) P230
絶対に失敗しないデータ分析
本書の最後のコラムとして「絶対に失敗しないデータ分析」があるのですが、このコラムは本書の最後に相応しいデータ分析という業務のそもそも論について語られている非常に示唆の富んだコラムになっています。
その中でも私が学びがあると思ったのは、以下の2つです。
- 仮説の否定が「失敗」ならデータ分析は当たり前に失敗する
- 引き受ける前に仮説検証を終わらせる
1つ目については、適切に依頼者の期待値をコントロールするか、もしくは仮説が成立しそうな分析案件しか引き受けないという選択肢が考えられます。
2つ目については、上記のどちらの戦略も取れなかった時に、カンニングをするかのように先にデータを受領してから仮説検証を終えてしまい、「成功」を確信してから案件を受注する、というテクニックです。
いずれにせよ、依頼者から見た「データ分析」や「AI」が『魔法のようなこと』『自分の結論を必ず後押ししてくれるもの』と認識されている可能性がある場合には、上記戦略はデータ分析者の身を守るお守りとして有用であると言えます。

まとめ
本記事では、データサイエンティストの転ばぬ先の杖的1冊「データ分析失敗事例集 失敗から学び、成功を手にする」について、現役DSである私が特に学びを得たと思ったポイントについて紹介させていただきました。
本書は本記事で紹介したトピックのみならず、それ以外にもたくさんの失敗事例が掲載されており、その経緯や「どうすれば良かったのか」という方針はどれも非常に参考になります。
本記事で興味を持っていただけた方はぜひ本書を手に取っていただけると幸いです!


コメント