
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
この記事では、sklearnのplot_partial_dependenceを使用してImportErrorが発生するときの対処法について解説いたします!
Partial Dependence Plotの簡単なおさらいも含め解決方法を解説しているので、同じ壁に当たってしまった方はぜひ参考にしてください!
そもそもPartial Dependence Plotとは
plot_parcial_dependenceの元となる、「Partial Dependence Plot(PDP)」とはある特定の特徴量の値を変化させたときに、予測モデルにどのような影響を及ぼすのかを可視化する手法です。
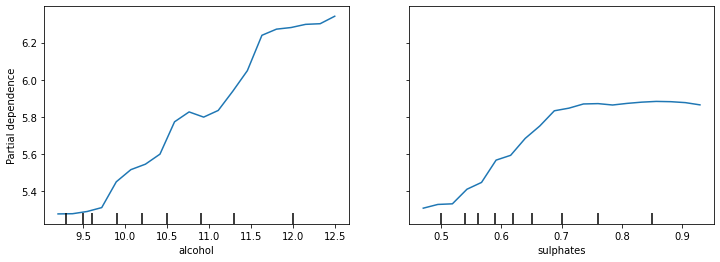
例えば、以下の図は、ワインの品質を予想するモデルの中で特に重要そうな「アルコール度数(alcohol)」と「硫酸塩(sulphates)」の値を動かした時のワインの品質のPDPです。
ハンズオンに使用するデータセットはKaggleより入手することができます。
参照:https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
左の図からはアルコール度数が高くなればなるほど品質が高いワインが多いことを表し、右の図は硫酸塩が0.5から0.7まではワインの品質の上昇に寄与するものの、0.7以上ではワインの品質は横ばいになることを表しています。
このようにPDPを使うことによって、複数の特徴量(今回のワインの例の場合は特徴量を11個持っていました)のうち、特定の特徴量の変化が目的変数(予想したい値)にどのような影響を及ぼすのかを知ることができるようになります。
PDPを作成する前のモデルの準備
ワインの品質に対するアルコール度数と硫酸塩の影響度をPDPで可視化するために、以下のコードでRandomForestの回帰モデルを作成します。
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
import matplotlib.pyplot as plt
df = pd.read_csv('winequality-red.csv', sep = ';')
display(df)
X = df.drop('quality', axis = 1)
y = df.quality
rf = RandomForestRegressor()
rf.fit(X, y)
plt.barh(X.columns, rf.feature_importances_)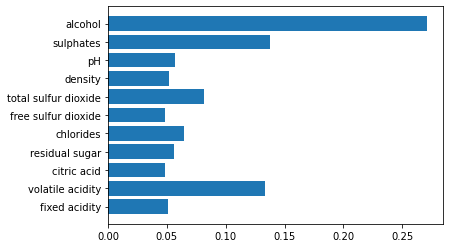
上記のコードを実行すると、特徴量重要度が可視化され、アルコール度数と硫酸塩がワインの品質を予測するのに重要な役割を果たすことがわかります。
エラーが発生するコード
上記で作成したRandomForestモデルにおけるアルコール度数と硫酸塩の影響度を可視化するために、以下のようなコードを実行するとImportErrorが発生します。
from sklearn.inspection import plot_partial_dependence
fig,ax = plt.subplots(figsize=(12, 4))
plot_partial_dependence(rf, X, ['alcohol','sulpahtes'],
grid_resolution=20, ax=ax);
上記のコードは以前は使用することができたのですが、現在はscikit-learnの仕様変更によってplot_partial_dependenceという関数がなくなってしまっています。
修正版のコード
以下が修正版のコードになります。
from sklearn.inspection import PartialDependenceDisplay
fig, ax = plt.subplots(figsize = (12,4))
PartialDependenceDisplay.from_estimator(rf, X, ['alcohol', 'sulphates'], grid_resolution=20, ax =ax)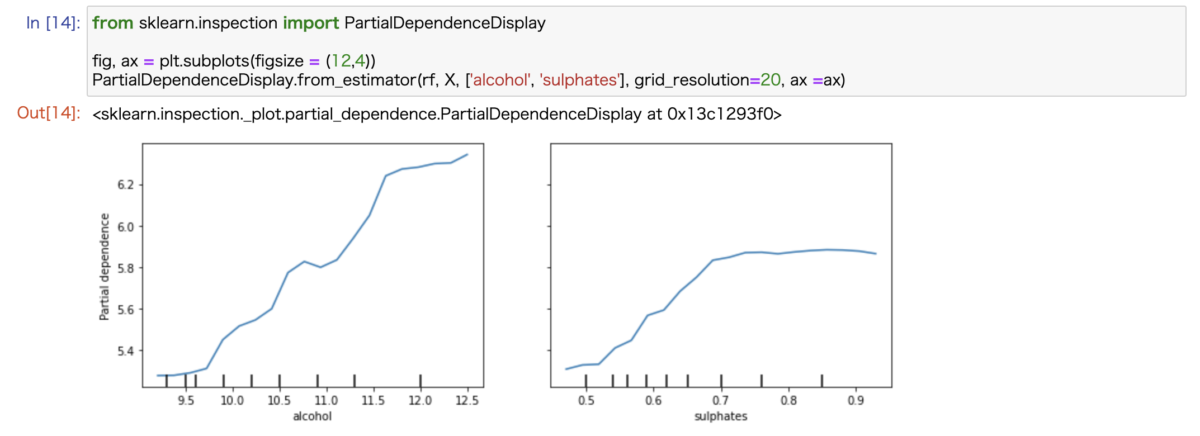
修正点はたったの2点です。
- plot_partial_dependenceの代わりにPartialDependenceDisplayというクラスをインポートするplot_partial_dependence関数の代わりにPartialDependenceDisplayのfrom_estimatorメソッドに各種引数を与えて可視化を行う
上記の修正だけで、アルコール度数と硫酸塩の値を変更させた時のワインの品質の変化を可視化することができました。
まとめ
この記事では、Partial Dependence Plotのおさらいをしつつ、scikit-learnの仕様変更によって使えなくなったplot_partial_dependence関数の代わりにPartialDependenceDisplayクラスを使ったPDPの可視化の方法を解説しました!
PDP自体は特徴量の目的変数への影響を可視化するのに非常に便利な手段なので、ぜひ活用してみてください!


コメント