
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
今回の記事では、大規模言語モデル入門の第5章 大規模言語モデルのファインチューニングにて、HuggingFaceのDatasetsからJGLUEのMARC-jaデータセットをダウンロードしようとしたら、
RuntimeError: The Amazon Review Dataset is currently no longer public.と出てしまった時の対処法を紹介します!
なんでこのエラーが出るの?
このエラーの原因はエラーコードにも書いてあるように、「Amazon Reviewのデータセットが公開データセットでなくなってしまったこと」が原因にあります。
以下のAWSの技術ブログにも書いてあるように、2023年9月時点からAmazon Review Datasetsの公開をストップしているようです。
その影響がJGLUEのMARC-ja(Multilingual Amazon Reviews Corpusのうち日本語レビューのみ抽出したもの)にも及んだということでしょう。
参考リンク:https://aws.amazon.com/jp/blogs/news/learning-to-rank-amazon-customer-reviews/
エラーが発生するコード
今回のエラーが発生するコードは以下です。
from pprint import pprint
from datasets import load_dataset
train_dataset = load_dataset(
'llm-book/JGLUE', name = 'MARC-ja', split = 'train'
)
valid_dataset = load_dataset(
'llm-book/JGLUE', name = 'MARC-ja', split = 'validation'
)
pprint(train_dataset[0])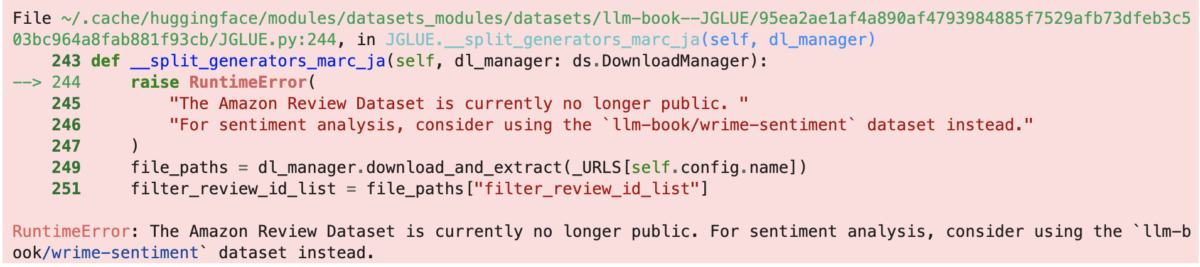
このコードを実行すると、最後のRuntimeErrorに記載のあるように、「Amazon Reviewデータセットはもう公開データではありません」と出てきてしまいます。
解決方法
解決方法はエラーコードの続きにもあるように、llm-book/wrime-sentimentという別のリポジトリのデータセットを使えばOKです。
修正版のコードは以下のようになります。
from pprint import pprint
from datasets import load_dataset
train_dataset = load_dataset(
'llm-book/wrime-sentiment', split = 'train'
)
valid_dataset = load_dataset(
'llm-book/wrime-sentiment', split = 'validation'
)
pprint(train_dataset[0])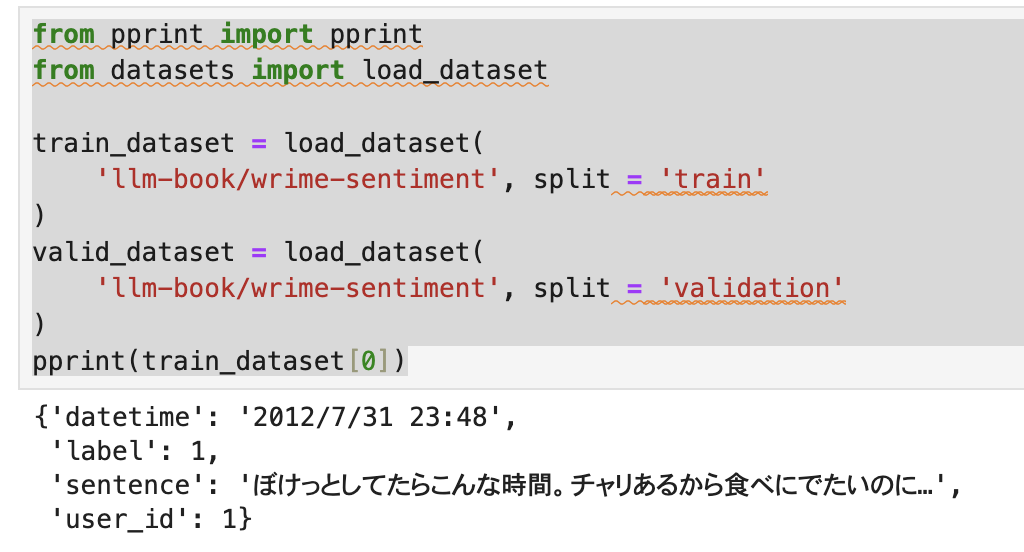
まとめ
今回の記事では、大規模言語モデル入門の第5章 大規模言語モデルのファインチューニングにて、HuggingFaceのDatasetsからJGLUEのMARC-jaデータセットをダウンロードしようとしたら、
RuntimeError: The Amazon Review Dataset is currently no longer public.と出てしまった時の対処法について紹介いたしました!
演習問題つきの実践書だとエラーが出るとドキッとすることも多いかと思いますので、本記事でサクッと解決して次の演習に進んでいただけると幸いです!


コメント