
こんにちは!データサイエンティストの青木和也(https://twitter.com/kaizen_oni)です!
今回の記事では、特徴量エンジニアリングについての知見を深めたい方必見の1冊『事例で学ぶ特徴量エンジニアリング』について、本書から得た学びを3選ご紹介いたします。
本書は、機械学習のモデルの精度を高めるためには、モデル選定やハイパーパラメータ調整など多様な手段がありますが、その中でも特徴量エンジニアリングにフォーカスしつつ、「なぜこのデータにこのような加工を施すのか」を懇切丁寧に解説した良書になります。
特徴量エンジニアリングについて改めて学習したデータサイエンティストの方、Kaggleでのスコア上げをモデル調整以外で取り組みたい方におすすめです!
本書の概要
本書では、特徴量エンジニアリングの基本的な手法から具体的な応用例までを扱っています。
Sinan Ozdemir『事例で学ぶ特徴量エンジニアリング』(O’reilly Japan/2023)Pv
本書は特徴量エンジニアリングについて、手法をひたすら紹介するのではなく、具体的なデータセットを取り上げながら、データセットの特徴に応じてどのようなデータ加工が有用なのかを紹介した特徴量エンジニアリングの良書です。
本書の章立ては以下の通りです。
- 1章 特徴量エンジニアリング入門
- 2章 特徴量エンジニアリングの基本
- 3章 ヘルスケア: COVID-19の診断
- 4章 バイアスと公平性: 再犯のモデリング
- 5章 自然言語処理 : ソーシャルメディアの感情分析
- 6章 コンピュータービジョン : 物体認識
- 7章 時系列分析 : 機械学習によるデイトレード
- 8章 特徴量ストア
- 9章 まとめと展望
本書から得た学び
本書から得た学びは以下の3つです。
- 特徴量から公平さを欠くバイアスを削除する方法
- モデルを固定することから見えてくる特徴量エンジニアリングの重要性
- 時系列分析における特徴量の作り方
順を追って解説していきます。
特徴量から公平さを欠くバイアスを削除する方法
本書においては、バイアスと公平性について論じる題材として、「少年が再犯するかどうかを予測するモデル」についての話が紹介されています。
上記の分析に使用するデータには、過去の犯罪に関するデータや再犯に関するデータ以外に、性別や国籍などの情報も含まれています。
「性別」や「人種」のようなデータを加味した上でモデルを作成すると、今後の再犯率の予測の際に「この人は男性だから女性よりも再犯率は15%高い」「この人は黒人だから白人よりも30%再犯率が高い」という、本人が変え難い特質による不公平な診断をしてしまう可能性があります。
一方で、「じゃあ性別や人種を取り除いてモデルを作ればいいだけじゃない?」と思いきや、それだけではモデルから不公正さを排除しきれないことが本書においては説明されています。
例えば、アフリカ系アメリカ人は刑事司法上における制度的な問題から、前科件数が他の人種の人と比べて優位に高くなってしまっています。
そのような場合には、たとえ特徴量としては人種というカテゴリを除いていたとしても、「前科件数」に人種の特徴が潜在的に表現されてしまっているので、やはりモデルとしては人種に対して不公平な診断をしてしまう可能性があります。
このような場合に、人種ごとの前科件数の平均値と標準偏差が0と1になるように調整することによって、人種によって不公平な診断を下す確率を下げることができます。
人を扱う分析については、気をつけなければ意図しない不公平を生み出してしまう可能性があることを本書の特徴量エンジニアリングを通して学ぶことができました。

モデルを固定することから見えてくる特徴量エンジニアリングの重要性
本書においては、ほとんどモデルにおけるハイパーパラメータなどに時間を使うことはせず、同一のモデルを使って「特徴量エンジニアリングだけでどれだけ予測の精度を向上されることができるか」に腐心しています。
データ分析にお熱な時期には、例えばKaggleなどのコンペティションに参加すると、ともかくハイパラ調整などでPublic Scoreを上げようと頑張ってしまうことがあります。
一方で、特徴量エンジニアリングはデータの傾向を把握するためにEDA(探索的データ分析)を行う必要があるし、特徴量エンジニアリングは行ったとしても徒労に終わることが多いので、あまり手をつけながちです。
その点、本書においてはあくまで特徴量エンジニアリングでできることを最大限に突き詰め、特徴量エンジニアリングによる差分を同一モデルを使うことで我々読者に伝わりやすくする工夫をしています。
そのようにして特徴量エンジニアリングの重要性を学ぶことによって、「もしかして、コンペ序盤は特徴量エンジニアリングに終始して、モデル選定はある程度外れていなければオッケー、コンペ終盤にモデルのハイパラ調整などのラストワンマイル的な努力の仕方をした方がいいのでは、、、?」と自身の根本にあるコンペ感がガラリと変わった音がしました。
特徴量エンジニアリングに関する本は多々読んできましたが、真に特徴量エンジニアリングだけに特化した本は本書だけであったと認識していますし、その点では本書に出会えてよかったとも思っています。

時系列分析における特徴量の作り方
書籍『経済・ファイナンスデータの計量時系列分析』を読んで、ARIMAモデルのような過去の値のラグを将来の値の予測のために使用するモデルについては学習をしてきましたが、それ以外の時系列分析向けの特徴量の作り方についてはあまり多くを知りませんでした。
一方で、過去を思い出せば、FX取引にハマっていた時には「移動平均線」「3標準偏差からの乖離」などをシグナルとして取引していました。
本書においては後者のような「過去のある程度の区間の統計量」を特徴量として使う方法について学ぶことができます。
時系列の特徴量エンジニアリングをKaggleデータセットで試してみた
それでは、実際に本書で学習した時系列データに対する特徴量エンジニアリングの一部をKaggleデータセットで試してみましょう。
使用するデータは電力消費量に関する「Electric_Production.csv」というデータです。

上記時系列データに対して、本書で紹介されていた3つの特徴量エンジニアリング手法を適用します
- ラグ特徴量
- ローリング特徴量
- エクスパンディング特徴量
そして、学習データと検証用データに2014年末を境目に分割した上で、重回帰分析を行います。
コードは以下のとおりです。
import pandas as pd
import statsmodels.api as sm
import numpy as np
df = pd.read_csv('/kaggle/input/electric-production/Electric_Production.csv')
# 日付のインデックス化
df.index = pd.to_datetime(df['DATE'])
del df['DATE']
# 1ヶ月前のラグ特徴量
df['feature__lag_1_month_ago_value'] = df['Value'].shift(1, freq = 'MS')
# 1年前のラグ特徴量
df['feature__lag_1_year_ago_value'] = df['Value'].shift(1, freq = pd.DateOffset(years = 1))
# 半年分のローリング特徴量
df['feature__rolling_value_mean_6'] = df['Value'].rolling(window = 6).mean()
# 1年分のローリング特徴量
df['feature__rolling_value_mean_12'] = df['Value'].rolling(window = 12).mean()
# エクスパンディング特徴量
df['feature__expanding_value_mean'] = df['Value'].expanding(12).mean()
# NaNデータの削除
df = df.dropna()
# 学習データ・テストデータ分割
def split_data(df):
train_df, test_df = df[:"2014-12-31"],df["2015-01-01":]
train_X, test_X = train_df.filter(regex = 'feature'), test_df.filter(regex = 'feature')
train_y, test_y = train_df['Value'], test_df['Value']
return train_df, test_df, train_X, train_y, test_X, test_y
train_df ,test_df, train_X, train_y, test_X, test_y = split_data(df)
# 重回帰分析
mod = sm.OLS(train_y, sm.add_constant(train_X))
result = mod.fit()
print(result.summary())
# 誤差の検証
y_pred = result.predict(sm.add_constant(test_X))
rmse = np.sqrt(np.sum((y_pred - test_y) ** 2) / len(test_y))
print()
print(f'RMSE: {rmse}')重回帰分析の結果と、誤差RMSEは以下の通りです。
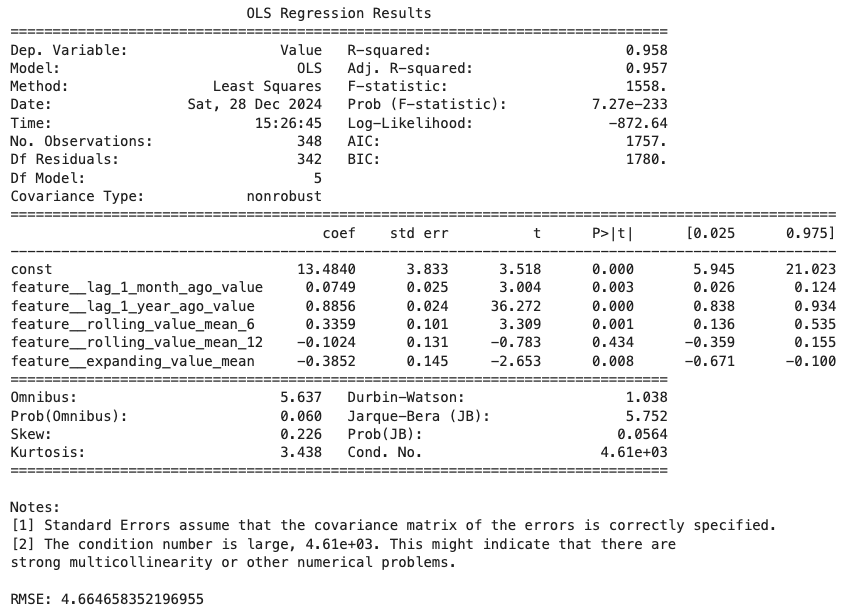
調整済み$R^2$が0.957と、かなり高い精度のモデルが出来上がっていることが分かります。
また、検証用データにおけるRMSEも4.66と、元のデータが50~130台であることを考慮するとかなり小さな誤差であることが分かります。
上記のように、重回帰分析という単純なモデルであっても、特徴量エンジニアリングによって精度の高いモデルを作成することができました。
まとめ
今回の記事では、特徴量エンジニアリングについての知見を深めたい方必見の1冊『事例で学ぶ特徴量エンジニアリング』について、本書から得た学びを3選ご紹介いたしました!
Kaggleなどのデータ分析において、モデル調整という近視眼的な考え方になっていた自身のマインドをいい意味で打ち砕いてくれた良書なので、特徴量エンジニアリングについてがっつり勉強したことはないな、Kaggle向けの特徴量エンジニアリングの書籍読んだけど、なんかしっくりこなかったんだよな、という方はぜひ読むことをお勧めいたします!


コメント